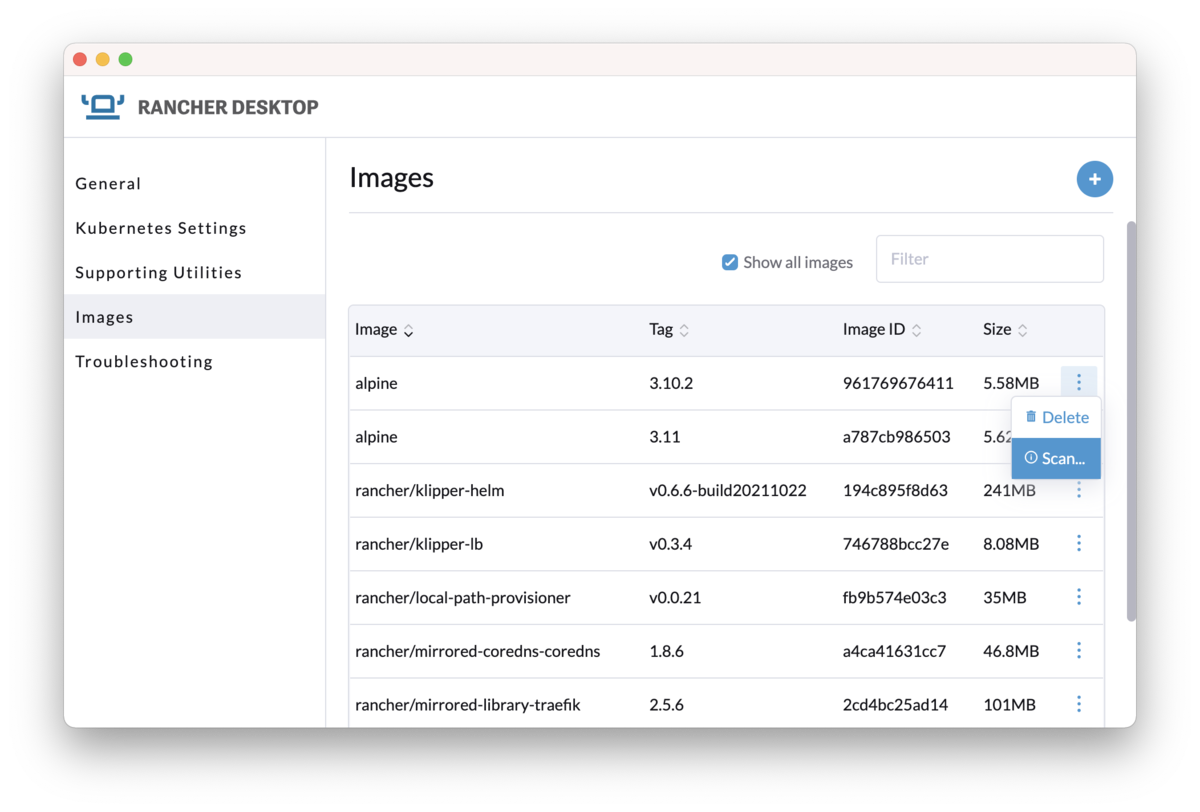
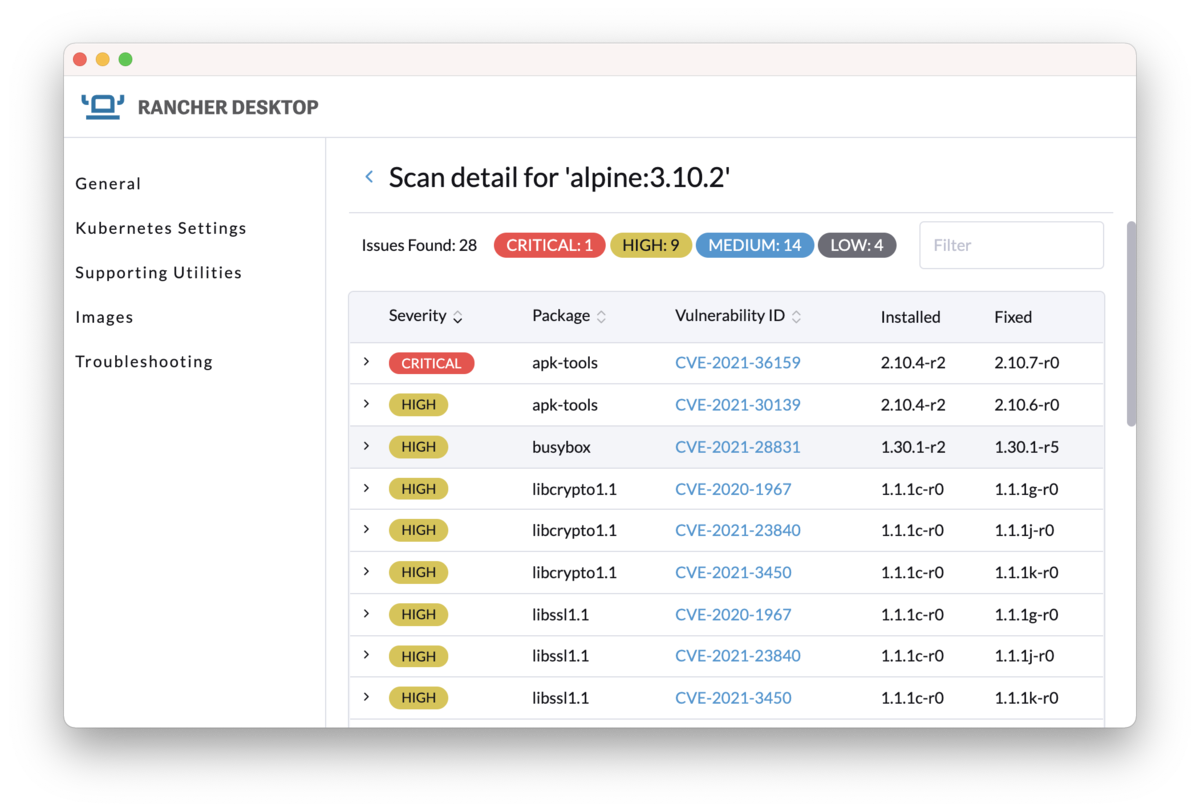
恐ろしく長い上に割と複雑なので最後まで読む人はほとんどいないと思うのですが、将来確実に忘れてしまう自分のために書いたので別に悲しくありません。
まえがき
鍵の管理不要でソフトウェア署名を可能にするKeyless Signingについて解説を書こうと思い、まず前提知識を書いていたら信じられないぐらい長くなったので前提知識だけで1つの記事になりました。
後述するsigstoreは急速に開発が進んでいるプロジェクトであり、ここで書いている記述は少し経ったら不正確になる可能性があります。本記事の内容は参考程度に留め、公式ドキュメントやソースコードなどを参照してください。昔はそうだったのかなぐらいで見てもらえればと思います。
また、最近認証や署名周りを追っていなかったこともあり、割と忘れていて用語の使い方が多少怪しいところがあるかもしれません。その場合はご指摘いただければ修正します。
PKIって何?とか公開鍵認証って何?とかそういうことは説明していません。
背景
近年開発されるサービスやソフトウェアはオープンソースソフトウェア(OSS)に依存することが一般的になっています。一方で、自分達が依存しているOSSの一覧を把握することは困難であり、さらにはそれらOSSがどこで管理されているのか、どのようにビルドされているのか、などを把握することはより困難です。その結果、いわゆるサプライチェーン攻撃を受けやすい状況になっています。サプライチェーン攻撃が何かはここでは説明しないので初耳の人は検索してみてください。
実際、サプライチェーン攻撃により大きな被害を受けた事例は近年多数あります。
medium.com
www.bleepingcomputer.com
そこで、ソフトウェアを誰がどのようにビルドしたのかを検証することが重要になるわけですが、そこで使われるのが電子署名の技術になります。中でもPGPによる署名検証は古くから利用されています。昔は権利関係で利用が難しかったようですが、今はGnuPG(GPG)やOpenPGPなどの別実装もありその辺りの問題はクリアされています。
しかし、結局鍵の管理が必要でそこがネックとなりあまり普及していません。そこで登場したのがsigstoreというLinux Foundation傘下のプロジェクトです。Red Hat, Google, Purdue University主導で2021年の3月に発表されました。"Sigstore"かと思いましたが、文の先頭でも"sigstore"と書いているので小文字が正解なんだろうと思っています。
www.linuxfoundation.org
今はOpenSSF傘下に移動しています。OpenSSFで行われていることと親和性が高い点、OpenSSFは大企業からの財政的支援を受けていることもありsigstoreのようなパブリックインスタンスを運用するプロジェクトにとって安定運用がしやすくなる点などが移動の理由のようです。
blog.sigstore.dev
上記のLinux Foundationのブログに書かれていますが、現在署名をするOSSプロジェクトはほとんどありません。鍵が漏洩したときの証明書の失効手続きだったり、公開鍵の配布だったり、OSSメンテナの負担が大きいためです。また、ユーザ側も信頼する鍵を入手して署名をどう検証するべきかを把握しておく必要があり負担となっています。シンプルにソフトウェアのダイジェストを公開している場合もありますが、ダイジェストが安全でないシステム上で公開されている場合が多く、すり替えや標的型攻撃を受けてしまう可能性があるという旨も書かれています。
Arch Linuxのパッケージメンテナの方も、電子署名の重要性は理解していてPGPを用いて署名を始めたが、PGP鍵のパスワードを忘れたり、PGP鍵の紛失をしたり、といったことが起きて大きな問題となったそうです。そのような事件を経験した後、多くのメンテナは署名することをやめたそうです。つまり、PGPによるソフトウェアの署名はうまくいっていないというのが現状です。
自分もOSSのメンテナなのですが、実際にDEBパッケージに署名をしていたPGP鍵を紛失して大きな問題になりました。正直紛失したとか恥ずかしくて今日まで黙ってきたのですが、多くのメンテナが同じやらかしをしてPGP署名を諦めているのを見て自分だけじゃなかったのかと安心しました。しかし自分が開発しているのはセキュリティツールであり、ソフトウェアやコンテナイメージに署名していないなんてありえないという声をいただくことがちょくちょくありました。やらなくてはと思いつつも2年ぐらい放置していたところに彗星のごとくsigstoreが現れました。
www.sigstore.dev
これは早く試さなくては、と思いつつもPGPの経験から署名しんどいしなーと腰が重く、かつ日々の開発に忙殺されて気づけば1年弱経ってしまいました。そうこうしているうちにsigstoreの方々から(実際にIssueをくれた人は現時点ではsigstoreのメンバーではないはずですが、sigstoreのプロジェクトで活動しています)Vulnerability Attestationの対応をお前のOSSでやらないかという声がけをして頂きました。
github.com
脱線しますが、そのあたりの仕様は以下にあります。
github.com
これは一度真面目にsigstoreと向き合わねばならないということで、ちょうど大きいリリースも終わったので気合いを入れて勉強したというのが背景です。
まだまだ理解しきれていない部分もあるのですが、sigstoreについての日本語での資料はほとんど見つからなかったので現時点での自分の理解でも役に立つかと思い書きました。
sigstoreの概要
sigstoreはソフトウェアサプライチェーンの真正性と完全性を確保しやすくすることで昨今の問題に対処することを目指すプロジェクトです。難しいのでざっくり言ってしまうと、ダウンロードしたソフトウェアが改ざんされておらず、かつ(そのソフトウェアが主張する)正しい人や場所でビルドされたことを担保するということです。ソフトウェアをダウンロードしたら実は攻撃者が改ざんして不正なコードを仕込んでた、みたいなことを防ぎたいよね、というのが解決したい課題です。
それだけ聞くとPGPで署名してたのと何が違うの?となると思いますが、一番大きく異なるのは可能な限り自動化をして極限までメンテナの手間を減らそうとしているところかと思います。上の sigstore.dev にも書いてあるようにOSSメンテナによるOSSメンテナのためのプロジェクトです。これは完全に主観なので本質はそこではない、みたいな指摘もあるかもしれません。
鍵管理の手間が減ることで鍵の漏洩や紛失リスクを下げますし、検証の手間も減らせればユーザにとっても信頼するソフトウェアだけを利用できるようになるため、OSSを利用する全ての人にとって利益があります。実際Keyless Signingという機能が実験的に公開されていますが、鍵の管理を不要にするもので今までの苦労から開放されることが期待されています。
上では署名・検証の労力と時間の削減についてのみ主観で話しましたが、今までと異なる点については sigstore.dev では以下の3つを挙げています。
- Automatic key management
- Transparent ledger technology
- Driven by our community
鍵の管理が自動化され、署名もtransparency logとして公の場所に保存されるため誰でも監査することが出来ます。簡単に無料で署名できるという点で、ソフトウェア署名におけるLet’s EncryptのようなものとGoogleは述べています。
security.googleblog.com
あとは企業主導ではなくコミュニティでやっているという点も強調しています。
ここで先に今の自分の理解を基にsigstoreに対しての個人的な主観を述べておきます。自分の理解が間違っていたら訂正します。sigstoreによって確かに鍵の管理から開放されたものの、現状のUIだと検証する側にはやはりしっかりとした理解が求められる気がします。検証できた気になっていて実は何も検証できていないということが起きそうで怖いです。ほとんどのソフトウェアが署名されていない現状と比べるとそれでも改善と言えるかもしれませんが、安全のはずと思いこむことでより攻撃に気づきにくくなる可能性についてはやはり不安です。ただし、この辺りはツールのUIの改善で何とか出来る部分かもしれません。
しかしそれらを考慮してもKeyless Signingは革新的なプロジェクトだと思いますし、ユーザ側の理解が進んでいけばメンテナの負担は劇的に削減されそうです。sigstoreの今後に期待したいですし、自分もVulnerability Attestationで声をかけてもらったので何か貢献できればと思います。
sigstoreを構成するツール群
sigstoreは、Cosign・Fulcio・RekorなどのOSSによるツール群です。Cosignは実際に署名をするために使うツールで、RekorはTransparency Logを提供し、Fulcioはソフトウェア署名のためのroot CAです。
Cosign
github.com
Cosignは鍵の生成から署名・検証を行うCLIツールです。署名方法は
- 通常の署名(良い呼び名が見つからなかった)
- Keyless Signing
の2つがあります。
また、署名対象としては大きく分けて
の2種類があります。なぜコンテナイメージだけ特別扱いされているかと言うと、OCI Distribution Specificationをうまく活用することで署名の保存位置を標準化しているためです。つまり署名を配布しなくてもCosignが勝手に取得してきてくれます。逆に言うとOCI RegistryじゃないとCosignはうまく署名できません(署名だけ別レジストリ指定したりも出来ますが)。OCI Distribution Specificationって何?というのを説明すると長くなるのですが、従来コンテナイメージしか置けなかったレジストリの仕様を拡張しファイルなら何でも置けるようにしたものぐらいの雑な理解で良いのではないでしょうか(怒られそう)。一応後半でもう少し説明します。コンテナイメージ以外の場合は従来どおり署名を自分で配布する必要があります。
Keyless Signingはそれ一つで記事にしようと思っているので、まずは通常の署名方法について解説します。
Rekor
github.com
RekorはSoftware Supply ChainにおけるTransparency Logを提供します。このTransparency LogはSSL/TLSサーバ証明書におけるCT(Certificate Transparency)と同様の機能です。CTについては以前軽くブログを書きましたが、CT自体の説明はしていなかったのでブログ内の参考URLなどを見てください。
knqyf263.hatenablog.com
ただし、Transparency Logは証明書の透明性だけでなく署名の透明性のためにも利用されます。要はソフトウェアが署名されたことをログとして記録し、それを誰でも確認できるようにします。さらにその署名のために発行された証明書も登録しておきます。このログを監査することで鍵の漏えい等を検知できるようになります。また、署名がされた当時に証明書やメールアドレスが有効であったことの確認などにも使えるのですが、その辺りはKeyless Signingで重要なので別の記事で説明します。
Rekorはログを検索するためのREST APIとTransparency Logを保存する役割を担います。しかしこのログが改ざんされてしまっては元も子もないので、ストレージにGoogleの開発したTrillianを利用し改ざん耐性を高めています。
github.com
元々CTを想定して作られたようなのでSupply Chain Transparency Logにおいても有用ということだと思います。Trillianについては自分もGigazineの記事を読んでふーんと思ったぐらいであまり知らないので、興味ある人は詳しくみてみてください。
gigazine.net
普段セキュリティで興味のある分野は論文を読むため、そのあとにまとめ系の記事を読むと不正確な記述が多いなと思ってしまうことが正直多いのですが、全ての一次ソースを読み切るのは難しいですし今回は重要な部分ではないので一旦「改ざんの困難なログシステム」なんだなぐらいの理解で先に進みます。
RekorはOSSとして公開されているため自分でRekorサーバを運用することも可能ですが、rekor.sigstore.dev などのパブリックインスタンスが公開されているためほとんどのユーザはそちらを利用することになり、Rekorを意識することはあまりないかもしれません。ちなみに現在ベストエフォートでの運用となっており、予告なしにサーバを落としたりリセットするかもしれないと注意書きされています。Experimentalと書かれているので良いのですが、ログがリセットされたらKeyless Signingでの署名検証に失敗するし既にKeylessで署名しているプロジェクトはどうなるんだろう...
docs.sigstore.dev
RekorのCLIも提供されており、上の検索APIなどはCLI経由で実行可能です。
Fulcio
github.com
GitHubリポジトリにSigstore WebPKIと書いてあるようにソフトウェア署名のためのRoot CAを提供します。
OpenID Connectのメールアドレスに基づき証明書を発行します。また、その証明書は有効期限が20分となっているため鍵をその後に紛失・漏洩しても失効の手間が不要です。そのOIDCを基に発行された証明書と上のRekorのTransparency Logを組み合わせることで署名時に有効なメールアドレスによって署名されたことが証明できます。
Fulcioで発行された証明書はTransparency LogとしてRekorに記録されます。Rekor同様にパブリックインスタンス(fulcio.sigstore.dev)が運用されています。ちなみにRekorと同様に2022/02/06時点ではまだWIPとのことです。
多くの場合はパブリックインスタンスを利用されることになるかと思います。ただしCTの問題点と同様にプライベートリポジトリのソフトウェアを署名してRekorにログを公開すると情報が漏洩してしまうため注意が必要です。その場合は署名を無効化したりプライベートインスタンスを立てたりする必要があります。
Rekorにログを保存したところで何かが防げるわけではなく監査が可能になるだけなので、自分のメールアドレスで証明書が勝手に作成された場合に通知を送るなど自分でログ監査する必要があります。
署名方法
RekorとFulcioはKeyless Signingの時に重要なのですが、今回の記事ではまず基本的な署名方法を説明するためCosignのみを使っていきます。混乱しやすいので以下の説明では一旦RekorとFulcioのことは忘れたほうが良いと思います。
コンテナイメージ
上で説明したようにコンテナイメージは特別なので先にコンテナイメージの署名について説明し、その後にBlobの署名を説明します。
鍵ペアの生成
まず鍵を生成します。Cosignは署名を簡単にするために多くのオプションは提供していません。署名アルゴリズムもECDSA-P256のみ対応のようです。生成時に秘密鍵のパスワードが聞かれるので強度の高いパスワードを入れます。
$ cosign generate-key-pair
Enter password for private key:
Enter password for private key again:
Private key written to cosign.key
Public key written to cosign.pub
デフォルトだとcosign.keyとcosign.pubというファイル名でそれぞれ秘密鍵・公開鍵が生成されます。
$ cat cosign.pub
-----BEGIN PUBLIC KEY-----
MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEfhj1XOKYLxMc9KzbZxXdU5dfBvNK
Oi2A2UKYGYMl3Cj8vvXNALWxhc2ZRWX1QypTa35ivrUU+ANRda4Gos3f9Q==
-----END PUBLIC KEY-----
秘密鍵は暗号化されたPEMとなっています。この秘密鍵はGitHub等においても安全で、CI上のパスワードマネージャで復号して署名することが出来るとsigstoreのブログで述べられています。
blog.sigstore.dev
通常の署名では鍵のペアを保管しておく必要がありますが、秘密鍵のパスワードだけちゃんと秘密に管理しておけば良く、公開鍵・秘密鍵はGitHub等に置いておけるため管理は比較的楽なのかと思います。暗号化された秘密鍵の例は以下です。
$ cat cosign.key
-----BEGIN ENCRYPTED COSIGN PRIVATE KEY-----
eyJrZGYiOnsibmFtZSI6InNjcnlwdCIsInBhcmFtcyI6eyJOIjozMjc2OCwiciI6
OCwicCI6MX0sInNhbHQiOiJxd1dNL09acFkwNHp0N28vNzE1ZTFDTVZGbDViSHJB
aE9NT1dURDJuMGlnPSJ9LCJjaXBoZXIiOnsibmFtZSI6Im5hY2wvc2VjcmV0Ym94
Iiwibm9uY2UiOiJuWm5QNzNGaFNsRFZ4NHhPTlplYkxZbUYvSTVEQmlXSyJ9LCJj
aXBoZXJ0ZXh0IjoiVG82ZSt4L0Nybk1TNUc0YUh0c1V3TlZRaW9vaUdNa0RhcGFW
SlBpRDJsMmdDMTdKRE1BZnp3TFFVSVhPUjVlMzNNdU9ObFZhekhNTGxsSzJJME5R
aGZhVWdWM0NqYlhoaHVNQ0xsaU1EOS9xRTRXSHBzZGxoZXpWSWw2VnJ1MGY0cERj
blJweEp1OTRYRGx1VWFid0VQZGNxMVVCc2NhRGd4NTRNNDBNZnBlVEYxTjJDMTBV
RE83L3Y4QkZScG83M01XejI2ZXRZTkdwb2c9PSJ9
-----END ENCRYPTED COSIGN PRIVATE KEY-----
上記ではファイルとして鍵ペアを管理する方法を説明しましたが以下のKMSに対応しているため、クラウドサービスを利用している場合は手元での鍵管理は不要になります。
- Azure Key Vault
- AWS KMS
- Google Cloud KMS
- Hashicorp Vault
YubiKeyなどのハードウェアキーにも対応しているようです。
github.com
また、ヘルプを見ていたらGitHubやGitLabの指定もできるようでした。
# generate a key-pair in GitHub
cosign generate-key-pair github://[OWNER]/[PROJECT_NAME]
どういうことかとピンとこなかったのでGitHubを試してみました。
$ export GITHUB_TOKEN=XXX
$ cosign generate-key-pair github://knqyf263/cosign-test
Enter password for private key:
Enter password for private key again:
Private key written to COSIGN_PASSWORD environment variable
Private key written to COSIGN_PRIVATE_KEY environment variable
Public key written to COSIGN_PUBLIC_KEY environment variable
Public key also written to cosign.pub
上記のようなメッセージが出たので手元の環境変数が設定されたのかと思って確認したのですがそんなことはなく、どうやら指定したリポジトリのSecretsに作成されるようです。
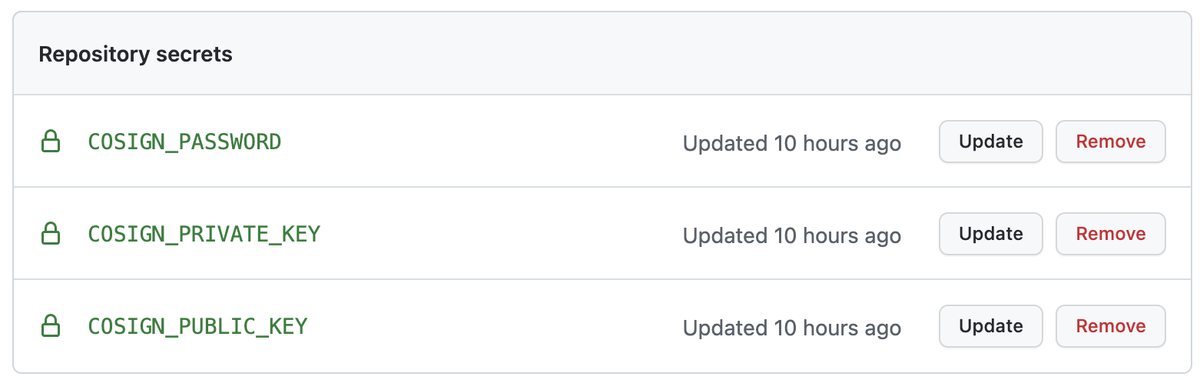
CI上で使うためかと思いますが、公開鍵と暗号化された秘密鍵はリポジトリに置いてパスワードだけ安全に管理すれば良いとブログに書いてたのに全部Secretsに入れるの...?という疑問は残りました。
署名
あとは上記で作った秘密鍵と署名したいコンテナイメージ名を指定するだけです。先程指定した秘密鍵のパスワードが求められます。
$ cosign sign --key cosign.key knqyf263/cosign-test
an error occurred: no provider found for that key reference, will try to load key from disk...
Enter password for private key:
Pushing signature to: index.docker.io/knqyf263/cosign-test
これで署名完了です。PGP等での署名に比べると複雑なオプションが隠されかなり簡素化されています。これだったらあまり詳しくない人でもとりあえず cosign sign 打っておこうとなって普及するかもしれません。
ただ1行目はプロバイダをしていないことでエラーが出ています。ファイルの秘密鍵を指定するのは一般的な方法なはずですが最初失敗したのかと勘違いしました。また、上の出力では “Pushing” 以降は自分が改行しましたが実際には Enter password for private key: の行に表示されるので最初ログ出力を見落としました。Cosignは先日1.0.0に到達したもののRekorやFulcioもまだunstableですし、こういう細かいユーザインタフェースを一つとってもまだ発展途上なプロジェクトという感じがします。
などとブログで文句を言うだけの人間になりかけたのでPRを出しました。一歩間違うと老害になるので日々恐怖と戦っています。
検証
検証時には公開鍵とコンテナイメージ名を指定するだけです。
$ cosign verify --key cosign.pub knqyf263/cosign-test [~/src/github.com/sigstore/cosign]
Verification for index.docker.io/knqyf263/cosign-test:latest --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- The signatures were verified against the specified public key
- Any certificates were verified against the Fulcio roots.
[{"critical":{"identity":{"docker-reference":"index.docker.io/knqyf263/cosign-test"},"image":{"docker-manifest-digest":"sha256:2da1196c0ebeed6ce7f462fe34e99f786d68c332701e428e98cec53fce29fe7f"},"type":"cosign container image signature"},"optional":null}]
これで終わり、と言いたいところですが実はこれでは不十分です。表示されているJSON内の critical.image.docker-manifest-digest の値と自分の手元にあるコンテナイメージのdigestを比較する必要があります。あくまで表示されているJSONの署名が正しい、つまりJSONの完全性と真正性を証明しただけで、今使おうとしているコンテナイメージについては何も証明できていません。この辺りは署名の保存方法に大きく関係するため、後述します。自分は最初その辺りでかなり混乱しました。
Blobs
コンテナイメージの署名方法を説明したのでBlobsについて説明します。こちらはコンテナイメージ以外全般という感じで、いわゆる一般的な署名です。テキストファイルやバイナリファイルに対して署名ができます。
鍵ペアの生成
これはコンテナイメージの手順と同じなので省略します。
署名
先程の sign コマンドとは別に sign-blob コマンドが用意されています。適当にファイルを作って署名してみます。先程と同様に秘密鍵とファイル名を指定します。また、署名はデフォルトだと標準出力に出されるので --output コマンドでファイルに書き出します。
$ echo hello > hello.txt
cosign sign-blob --key cosign.key --output hello.txt.sig hello.txt [~/src/github.com/sigstore/cosign]
WARNING: the '--output' flag is deprecated and will be removed in the future. Use '--output-signature'
Using payload from: hello.txt
an error occurred: no provider found for that key reference, will try to load key from disk...
Enter password for private key:
Signature wrote in the file hello.txt.sig
これで完了です。先程とは異なり、公開鍵に加え署名も何かしらの方法で配布する必要があります。
検証
検証時には何かしらの方法で手に入れた公開鍵と署名を使います。Blob用には verify-blob コマンドが用意されているのでそちらを実行すると Verified OK と表示されます。
$ cosign verify-blob --key cosign.pub --signature hello.txt.sig hello.txt
Verified OK
コンテナイメージの場合と異なり hello.txt のハッシュ値を取って署名と比較する部分までCosignが行ってくれるため、これで検証は完了です。当たり前ですが改ざんすると検証は失敗します。
$ echo hello >> hello.txt
$ cosign verify-blob --key cosign.pub --signature hello.txt.sig hello.txt
Error: verifying blob [hello.txt]: failed to verify signature
main.go:46: error during command execution: verifying blob [hello.txt]: failed to verify signature
署名の仕組み
使い方だけ知りたいという人もいるかも知れないので詳細は分けましたが、本題はこちらです。使い方はドキュメントを読めばすぐ分かる話ですし変わる可能性もあります。ただ仕組みは一度理解しておくと応用が効くと思うので細かめに書いておきます。
コンテナイメージ
OCI Registryについて
上でも書きましたがOCI Distribution Specificationを活用しています。コンテナイメージのpushやpullの時に何が行われているのかを知っている人は問題ありません。もし全く知らないという人は以下のブログに目を通してみてください。こちらはDocker Registry HTTP API V2なのでOCIではないのですが、OCIはDockerを基に作られているので似たようなものと思って良いです。
knqyf263.hatenablog.com
一応軽く説明しておくと、OCIレジストリに保存できるものをOCI Artifactsと呼びますが(コンテナイメージはArtifactの一種)、これは
の3つで構成されています。manifest内にconfigとblobへの参照(SHA256のダイジェスト)が含まれています。このblobはいわゆるレイヤーなのでそのArtifactの実体です。blobにはmedia typeが指定でき、以前はコンテナのレイヤーしか受け付けていませんでしたが、OCIレジストリではコンテナイメージ以外でも受け入れられるようになりました。本当に何でも置けるので最近はただのクラウドストレージとして利用されている感があります。例えばHomebrewで brew installするとGitHub Packages Container registryからビルド済みのファイルだったりをダウンロードします。
とにかくmanifestを最初に取ってきて、その中に書かれている実体などをその後に取得するんだなという理解で今回は問題ないと思います。言葉で説明されてもわからないと思うので google/go-containerregistry で提供されている craneコマンドを使ってマニフェストを見てみます。
$ crane manifest knqyf263/cosign-test | jq .
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"config": {
"mediaType": "application/vnd.docker.container.image.v1+json",
"size": 587,
"digest": "sha256:b3430291e4c4c0c296c11ece55a597f52d06820f04ce48327158f978ef361056"
},
"layers": [
{
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"size": 122,
"digest": "sha256:7eb443b114bf9f19adff19ab6e15b3715fb6b1d06ad3ad0b4bc945fac80a7eda"
},
{
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"size": 131,
"digest": "sha256:a31e0a5a52ef3648969a3bdb9b06d45811c7cb1132d0bf047be701a1ec5a7eaf"
}
]
}
knqyf263/cosign-test というコンテナイメージのmanifestを取得しました。タグは省略したので latest です。layersの下に2つオブジェクトがあるように、このイメージは2つのレイヤーで構成されていることがわかります。あとはlayers.digestに従ってblobを取得することでコンテナイメージの本体が手に入ります。OCI Image Manifestについて詳しくは以下を参照してみてください。
github.com
ところが実際には最近はマルチプラットフォーム対応のためにOCI Image Indexが使われており公式イメージなどに対して上のコマンドを打っても異なるフォーマットのJSONが返ってくると思います。そのへんについて説明し始めると永遠に署名にたどり着けないですし本題と関係ないのでスルーします。一応仕様だけ貼っておきます。
github.com
署名の保存先
さて本題に戻ると、OCIレジストリ上にあるコンテナイメージに署名し、それをさらにOCI Artifactとしてレジストリにpushしてしまおうというのがsigstoreのコンテナイメージ署名の裏側です。そのpush先の決め方ですが、仮に gcr.io/dlorenc-vmtest2/demo:latestが指定された場合は以下のようになります。
latest というタグを sha256:97fc222cee7991b5b061d4d4afdb5f3428fcb0c9054e1690313786befa1e4e36 というダイジェストに変換する: を - に置換し、suffixに .sig をつける- 2で生成した文字列をタグ名として扱い、元のリポジトリと合わせて
gcr.io/dlorenc-vmtest2/demo:sha256-97fc222cee7991b5b061d4d4afdb5f3428fcb0c9054e1690313786befa1e4e36.sig にする
3は別レジストリやレポジトリも指定できるようですが、一旦は同一リポジトリ想定で良いと思います。詳細は以下です。
github.com
1の変換方法ですが、これはmanifestを取得してそのダイジェストを使っています。実際にはHTTPのレスポンスヘッダに値が埋め込まれるので自分で計算しなくても良いですが、とにかくmanifestの内容をハッシュ計算に利用しています。
署名フォーマット
では先程署名した knqyf263/cosign-test:latest を見てみます。まずmanifestのハッシュ値を計算します。
$ crane manifest knqyf263/cosign-test | sha256sum
2da1196c0ebeed6ce7f462fe34e99f786d68c332701e428e98cec53fce29fe7f -
上のルールに則れば sha256-2da1196c0ebeed6ce7f462fe34e99f786d68c332701e428e98cec53fce29fe7f.sig がタグ名になるはずです。つまりイメージ名は knqyf263/cosign-test:sha256-2da1196c0ebeed6ce7f462fe34e99f786d68c332701e428e98cec53fce29fe7f.sig になります。このマニフェストを取得してみます。
$ crane manifest knqyf263/cosign-test:sha256-2da1196c0ebeed6ce7f462fe34e99f786d68c332701e428e98cec53fce29fe7f.sig | jq .
{
"schemaVersion": 2,
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"config": {
"mediaType": "application/vnd.oci.image.config.v1+json",
"size": 233,
"digest": "sha256:4d79105ee210d241894b218aa44829bdcdf9bfbca105aa337039586828cfa239"
},
"layers": [
{
"mediaType": "application/vnd.dev.cosign.simplesigning.v1+json",
"size": 252,
"digest": "sha256:41eeee6c4ffaca4045c86b368150c089c75144fc248bf2ea94ffb414f322438f",
"annotations": {
"dev.cosignproject.cosign/signature": "MEQCIH/1onF2jIZ0X+CHMQdPGYn3hcdykevfPdNKIQTZvs9nAiAS2OygqY+nxfytHi1AMrG1lCy5zI57FgzNLQti/fYxfw=="
}
}
]
}
確かに取得できました。ちなみに今は手動で署名のタグを生成しましたが、Cosignには triangulate というサブコマンドがあり署名の保存先を教えてくれます。triangulateっていうコマンドおしゃれすぎない?
$ cosign triangulate knqyf263/cosign-test
index.docker.io/knqyf263/cosign-test:sha256-2da1196c0ebeed6ce7f462fe34e99f786d68c332701e428e98cec53fce29fe7f.sig
もちろんこんなイメージをpushした覚えはないのでCosignが勝手にpushしたということになります。layers.annotationsの下にsignatureが置かれているのが見えると思います。これが署名の実体です。
では何に対して署名しているのか?と疑問に思うかもしれません。今まで見てきたようにOCI Registry上にあるコンテナイメージというのは仮想的な概念です。manifest, config, blobで構成されるものをイメージと呼んでいるだけで、上の hello.txt のように署名可能なファイルシステム上のオブジェクトは存在しません。そこで、代わりにmanifestに対して署名しているというわけです。manifestの中にあるblobなども全てdigestで参照されているため、その値を改ざんするとmanifestのdigestも変わってしまいます。つまりmanifestのdigestというのはイメージ全体のdigestのように見立てることが出来るというのがポイントです。
このmanifestのdigestに対して署名をすれば終わりなわけですが、メタデータが欲しい場合もあるかもしれないということで、Red Hatにより提案されていたSimple Signingが採用されました。
www.redhat.com
manifestのdigestに加え複数のフィールドを持てるJSONとなっており(signature claimと呼ばれている)、以下のようなフォーマットになっています。
{
"critical": {
"identity": {
"docker-reference": "testing/manifest"
},
"image": {
"Docker-manifest-digest": "sha256:20be...fe55"
},
"type": "atomic container signature"
},
"optional": {
"creator": "atomic",
"timestamp": 1458239713
}
}
optionalフィールドがあるため、自分で好きな値を署名に入れ込むことも可能です。ちなみに自分は critical とかいまいちピンときませんでしたしSimple Signingちょっと微妙なフォーマットだなと思ったのですが、sigstoreの創業メンバーでChainguard CEOのDanさんもクセがあって好きじゃないと言っていて笑いました。
blog.sigstore.dev
とはいえ必要なフィールドが全て定義されているので、とりあえずこれで行こうとなったようです。最近は何でも独自フォーマットを定義する人達に苦しめられているので、既存の資産を活用する姿勢は好きです(脱線)。
さて、ではこのsignature claimはどこにあるのかというとblobの中にあります。上記manifest内のblob digestを使って取り出してみます
$ crane blob knqyf263/cosign-test@sha256:41eeee6c4ffaca4045c86b368150c089c75144fc248bf2ea94ffb414f322438f | jq .
{
"critical": {
"identity": {
"docker-reference": "index.docker.io/knqyf263/cosign-test"
},
"image": {
"docker-manifest-digest": "sha256:2da1196c0ebeed6ce7f462fe34e99f786d68c332701e428e98cec53fce29fe7f"
},
"type": "cosign container image signature"
},
"optional": null
}
確かにsignature claimのJSONが取り出せました。
署名検証
あとはこのJSONのdigestとmanifest内の dev.cosignproject.cosign/signature を使って署名検証すればOKです。ここはCosignが勝手にやってくれるところですが、今回は自分で試したいのでopensslコマンドを使います。まずはsignatureを取り出し、Base64デコードします。
$ crane manifest knqyf263/cosign-test:sha256-2da1196c0ebeed6ce7f462fe34e99f786d68c332701e428e98cec53fce29fe7f.sig | jq -r '.layers[0].annotations."dev.cosignproject.cosign/signature"' | base64 -d > knqyf263-cosign-test.sig
上のsignature claimをファイルに書き出します。
$ crane blob knqyf263/cosign-test@sha256:41eeee6c4ffaca4045c86b368150c089c75144fc248bf2ea94ffb414f322438f > knqyf263-cosign-test.json
では公開鍵を使って署名検証を行います。
$ openssl dgst -sha256 -verify cosign.pub -signature knqyf263-cosign-test.sig knqyf263-cosign-test.json
Verified OK
ということでこのJSONは改ざんされていないことが証明できました。かつ公開鍵を配布していた人が生成したことも証明できます。しかしここで重要なのは、このJSONが正しいのであって自分の使いたいイメージが改ざんされていないかどうかは何も証明していないという点です。
署名と公開鍵を使って検証を行ったので何か終わった気になりますが、実際には違います。署名が二段階になっているのでややこしいです。つまり、図にすると以下のようになっています。

- OCI Image Manifestのハッシュ値をSHA256で計算する
- 1で得られたダイジェストをSimple Signingで定義されたJSONに埋め込む
- 2で得られたJSONのハッシュ値をSHA256で計算する
- 3で得られたダイジェストを秘密鍵で暗号化する
あとは得られたSignature Claimをblobとしてpushしたり、manifest内のdev.cosignproject.cosign/signature に4で得た署名を入れてmanifestをpushしたりします。自分の理解が正しければ、本来のSimple Signingだと直接JSONを暗号化していたはずなので3のSHA256の部分はなかったはずで、sigstoreでの使い方は少し異なる気がします。勘違いだったらすみません。
ここまでの説明で署名がどう行われているか理解できたはずなのでようやく cosign verify に戻ります。 cosign verify が検証で行っていることを図にすると以下です。
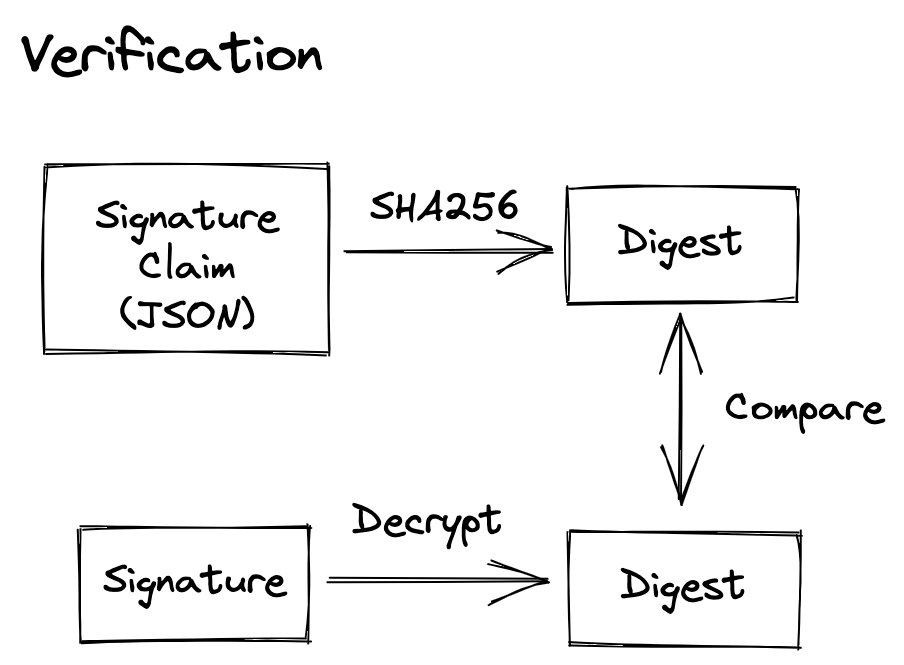
上の署名の図と比較すれば分かりますが、一番比較したいはずのOCI Image Manifestのdigestとの比較はありません。つまり cosign verify しただけでは終わりではなく、以下のステップが必要になります。

自分が使おうとしているイメージのdigestを取得して、その値がSignature Claim内の docker-manifest-digest と比較することで初めてそのイメージの検証が終わったと言えます。cosign verify-blob では Verified OK と表示していたのに cosign verify ではそういった表示がなくただSignature ClaimのJSONが表示されるのはこういう理由だと理解しています。
検証が不十分な例
実際、sigstoreのブログで以下のように書かれています。
But, all we’ve really verified is that a random object we found somewhere was signed. We didn’t prove any relation at all to the image we tried to verify!. Tags are mutable and our naming scheme itself is not secure. We need to inspect the payload we took such care to create earlier.
The value here MUST match the value of the digest of the image we fetched at the start of this process. Once that check is complete, we can now prove that the signature payload was “attached” by reference to the original container image that was signed.
Cosign Image Signatures
CosignのREADMEにも書かれています。
Note that these signed payloads include the digest of the container image, which is how we can be sure these "detached" signatures cover the correct image.
https://github.com/sigstore/cosign/blob/6ed068a7d8dd846661b401004db85fbb743e6db5/README.md?plain=1#L89-L90
以下の部分に着目してどのようなケースで問題になるかを説明します。
Tags are mutable and our naming scheme itself is not secure.
まず、タグというのはただのaliasなのでタグが示す実体というのは変わり得ます。 latest が分かりやすい例だと思います。通常のタグ運用では、新たなイメージがpushされるたびに latest が指すものは変わっていきます。そこで以下のような例を考えます。
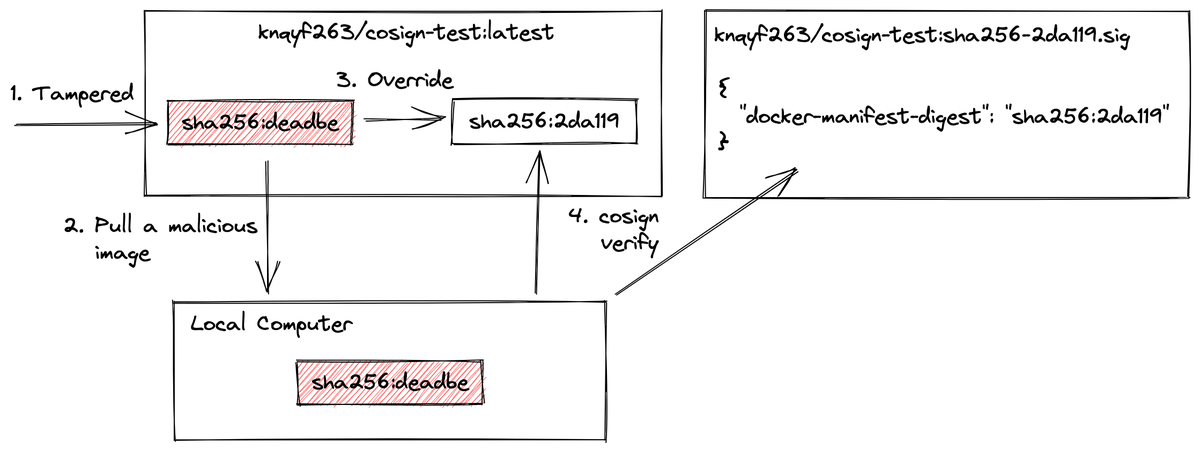
- 攻撃者が
knqyf263:cosign-test:latest として悪意あるイメージをpush
- ユーザは気付かずにそのイメージを手元にpull(
sha256:deadbe )
- その後CIなどの正規のフローによってlatestが更新される(
sha256:2da119 )
cosign verify を実行するが、新しい方の latest を検証するため検証は成功する
ここで cosign verify はリポジトリ上のイメージを見てその署名を検証するというところが重要です。手元にある不正な sha256:deadbe については関知しません。つまり、単に knqyf263/cosign-test:latest が指している sha256:2da119 が改ざんされていない正規のイメージであることを証明しただけで、実質無意味な状態で終わっているのです。手元にある自分のイメージが sha256:2da119 であることを検証して初めて完了になります。
訂正:もう一つの例を紹介していたのですが、自分の検証が間違っており実際にはきちんと検知されたため削除しました。@lmt_swallow さんありがとうございます。
https://twitter.com/lmt_swallow/status/1490326991840497667
上の例では手元には sha256:deadbe があり、今検証に成功したのは sha256:2da119 なのでそれらのdigestを比較すれば本来検知できるものです。図で言うと以下の赤のバツの部分です。

しかし cosign verify で検証が終わったと勘違いしてしまうとこのような攻撃は検証をすり抜けてしまいます。
つまり署名の保存方法をきちんと理解しておかないと署名検証を正しく完了できない可能性があります。実際Cosignの入門的なブログを見てもほぼ全てが cosign verify を打って終わりとなっています。
再度になりますが、 cosign verify はあくまでレジストリ上にある knqyf263/cosign-test:latest の署名を見て上のSignature ClaimのJSONの真正性と完全性を証明したのであって、それは自分の検証したいコンテナイメージとは何も関係がありません。上のREADMEで"detached"な署名と書かれているのはそういう理由です。手元のイメージが上のdocker-manifest-digestと一致する、またはまだpullしていないのであればタグではなくdigestを指定してpullするなどの操作が必要になります。
$ docker pull knqyf263/cosign-test@sha256:2da1196c0ebeed6ce7f462fe34e99f786d68c332701e428e98cec53fce29fe7f
それを経て初めて上の署名が自分の使いたいコンテナイメージのものであるということが証明できます。手元のdigestを確認するにはRepoDigestを見るぐらいしか自分は思いつかなかったのですが(Image IDはmanifestではなくconfigのdigest)、この辺り説明しているドキュメントが見つからずこんな方法で良いのか不安です。
$ docker inspect knqyf263/cosign-test | jq '.[0].RepoDigests'
この最後のdigest検証部分がほとんどの第三者による入門ブログには記載されておらず、sigstoreのメンバーしか理解していないのではないかと不安になっています。またはSignature Claimの完全性を証明しただけなんだから実際使うコンテナイメージとの紐付けを確認するのは常識過ぎて誰も触れていないのか、あるいは自分の理解が間違っていてそんなことは一切不要で cosign verify で完結しているかのいずれかでしょう。もし1つ目だとするとほとんどの人がうまく検証できていないことになりますし、不安で仕方ないので有識者の意見を歓迎します。
GitHubのブログでもThat’s pretty coolで終わっていそうな雰囲気で不安です。ただ上のSignature Claim内のoptionalなフィールドにgit refを入れる方法は紹介しているので、そっちで確認してねということでしょうか。何れにせよサプライチェーン攻撃の自動検知の方法は紹介されておらず、後追いで監査する方法に留まっているように見えます。
ただこの辺まで含めてCosignで自動検証することは可能だと思うので、今後改善されていくのかもしれません。
Blobs
テキストファイルやバイナリファイルの署名についても一応書こうかと思いましたが、上のコンテナイメージの署名フローのSignature Claimを省略しただけですし、そもそもただの一般的な署名なので説明は省きます。コンテナイメージ署名の説明で疲れました。
参考
まとめ
ソフトウェア署名は人類には難しすぎて何十年もの間放置されてきましたが、近年のサプライチェーンセキュリティ問題の深刻化によりここ数年で一気に動き始めたように見えます。