良い話を含むので概要の最初だけでも読んでもらえると幸いです。この話が実用的かと言うと多分全然実用的ではないので理解しても仕方ないかなと言う気がします。
概要
先日Dirty PipeというLinuxカーネルの脆弱性が公表されました。
この脆弱性の原理自体も面白いのですが、その前に報告者の組織で行っているGzipとZIPの処理で引っかかったのでまず先にそちらの理解に努めました。ちなみにアホなのでDirty Pipe関連で不明点を報告者に直接ぶつけたら丁寧に回答してくれました。話題になっていて問い合わせも殺到しているはずなのに返信がいつも数時間以内でありがたい限りです。疑問が解消してスッキリして最高な気分になれたので、失礼かもみたいな気持ちを一度捨てて無理を承知で連絡をとってみると良いかもしれません。忙しければスルーされるだけなので、そこまで時間を取ってしまうこともないと思います。そういったことで関係が生まれて何かに繋がるかもしれません。ちなみに自分もOSSのメンテナをやっていて知らない人からメールがちょくちょく来ますが面倒な時はただスルーしてますし、特に嫌な気持ちにはなりません。
話を戻すと、まずは上記ブログ内に以下の記述がありました。
Via HTTP, all access logs of a month can be downloaded as a single .gz file. Using a trick (which involves Z_SYNC_FLUSH), we can just concatenate all gzipped daily log files without having to decompress and recompress them, which means this HTTP request consumes nearly no CPU.
こちらは簡単です。まず報告者の組織で提供しているサービスでは、Webサーバのログを日にちごとにgzipで保存していて、一ヶ月単位で丸ごと落とすことも可能になっています。gzipは仕様的にgzip同士を連結しても正しいgzipファイルとなるので、それを活用して日にちごとのgzipファイルを連結して1ヶ月分のgzipファイルとしているということだと思います。以下のようなイメージです。
$ cat 20220301.log.gz 20220302.log.gz 20220303.log.gz > 202203.log.gz
この辺りは以前以下のブログで説明したので興味あれば見て下さい。
次に、
Memory bandwidth is saved by employing the splice() system call to feed data directly from the hard disk into the HTTP connection, without passing the kernel/userspace boundary (“zero-copy”).
こちらの説明も簡単です。 splice(2) システムコールを使うことでユーザ空間にいちいちコピーせずともgzipファイルの連結が可能ということです。spliceについての説明は調べれば出てくるので詳細は省きますが、ファイル等からカーネル空間のページキャッシュに読み込み、それを直接パイプに渡せます。ファイルごとの処理が特に必要ではなく順番に連結するだけなので、これは難しくないと思います。
問題は次です。
Windows users can’t handle .gz files, but everybody can extract ZIP files. A ZIP file is just a container for .gz files, so we could use the same method to generate ZIP files on-the-fly; all we needed to do was send a ZIP header first, then concatenate all .gz file contents as usual, followed by the central directory (another kind of header).
gzipはWindowsで使えないから代わりにzipにしているということですが、zipは単に複数gzipファイルの入れ物でしかないからgzipの連結と同様にzipファイルも作れると言っています。まずzipヘッダを作り、次にgzipファイルを連結し、最後にcentral directoryヘッダを付ければ良いと言っています。
正直かなり混乱しました。確かにzipとgzipはどちらも圧縮アルゴリズムとしてDeflateが使えます。そのため圧縮したファイルそのものは同じになる可能性がありますが、仕様としては全然別物なのでヘッダやフッタのフォーマットも異なります。zipはアーカイバとしての機能もありますしgzipは圧縮のみです。もちろん一度展開すれば変換は容易ですが、CRCとかもあるのにgzipファイルの中身をユーザ空間のメモリに載せずただ連結するだけで行けるもんなの?!というのが疑問でした。
あとで分かりましたが、ここを理解しないと脆弱性の細かい理解も難しいです。
ファイルフォーマット
まず最初にgzipとzipのフォーマットについて軽く見ていきますが、ググると大量のドキュメントやブログがあるのでそちらを見てもらったほうが確実かもしれません。
gzip
RFC1952 を見るとフォーマットは以下のようになっています。gzipの仕様に詳しくなりたいわけではないのでオプショナルなヘッダは省略しています。
+---+---+---+---+---+---+---+---+---+---+ |ID1|ID2|CM |FLG| MTIME |XFL|OS | (more-->) +---+---+---+---+---+---+---+---+---+---+ +=======================+ |...compressed blocks...| (more-->) +=======================+ 0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | CRC32 | ISIZE | +---+---+---+---+---+---+---+---+
大きく分けて4つのパートがあります。
- 10-byteのヘッダ
- オプショナルな拡張ヘッダ(上の図では省略)
- DEFLATEで圧縮されたファイル本体
- 8-byteのフッタ(trailer)
10-byteのヘッダ
+---+---+---+---+---+---+---+---+---+---+ |ID1|ID2|CM |FLG| MTIME |XFL|OS | (more-->) +---+---+---+---+---+---+---+---+---+---+
まずはgzipであることを示すために2バイトのマジックバイトが来ます(0x1f 0x8b)。次に圧縮方法(CM, Compression Method)が来ます。CMが8の場合はDeflateを意味します。gzipでは通常Deflateが利用されます。そして次にフラグですが、この値によって拡張ヘッダの有無が決まります。フラグの各ビットの意味は以下のとおりです。
bit 0 FTEXT bit 1 FHCRC bit 2 FEXTRA bit 3 FNAME bit 4 FCOMMENT bit 5 reserved bit 6 reserved bit 7 reserved
この辺は任意なので気にせずで良いですが、FNAMEはファイル名が入っているので普通にコマンドラインからgzip作ると埋められると思います。
ヘッダの残りは圧縮されている元ファイルの最終更新時刻や拡張フラグやOSなどが入ります。
拡張ヘッダ
上のフラグによって決まります。例えばFNAME がセットされていれば、元ファイルの名前が存在しゼロバイトによって終端されます。詳細はRFCが分かりやすいです。
ファイル本体
上で指定された圧縮アルゴリズムによって圧縮されたブロックです。
フッタ(trailer)
gzipのtrailerは8バイトで、CRC-32とサイズが4バイトずつ含まれています。
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | CRC32 | ISIZE | +---+---+---+---+---+---+---+---+
zip
まずは大雑把に内容を掴むため、Wikipediaの図を引用します。

各ファイルの前にヘッダ(ローカルヘッダ)と、索引用途のヘッダ(セントラルディレクトリ)で構成されていることが分かります。ファイルエントリ自体は各ローカルヘッダのあとに置かれています。ヘッダについてもう少し細かく言うと
の4つがあります。複数のファイルとセントラルディレクトリエントリを入れることが出来て、次のようなレイアウトになります。
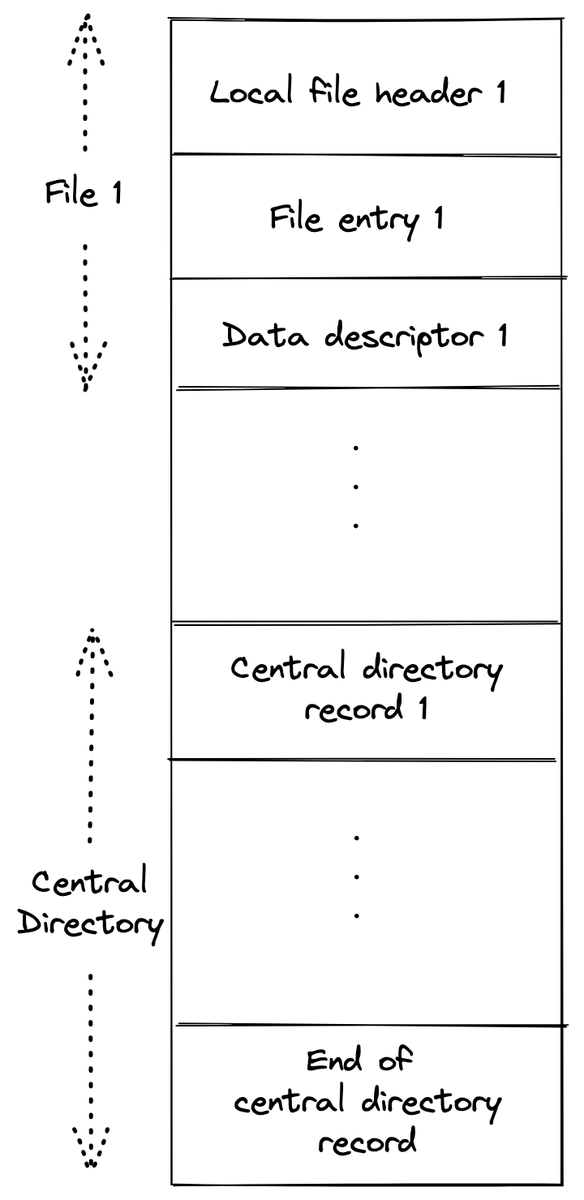
以下で1つずつ見ていきます。
ちなみに以下を参照していますが、zipのRFCとかはないのでしたっけ...?その辺の歴史に詳しくないので誰か詳しい人が教えてくれたら追記します。 https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT
ローカルファイルヘッダ
これは上でも述べたように各ファイルの前につくヘッダで、以下のようになっています。
local file header signature 4 bytes (0x04034b50) version needed to extract 2 bytes general purpose bit flag 2 bytes compression method 2 bytes last mod file time 2 bytes last mod file date 2 bytes crc-32 4 bytes compressed size 4 bytes uncompressed size 4 bytes file name length 2 bytes extra field length 2 bytes file name (variable size) extra field (variable size)
この中でまず重要なのはcompression methodで、圧縮メソッドが指定できます。デフォルトでは8で、Deflateになります。zipではかなり多くの圧縮メソッドが利用可能です。ただ、0が非圧縮で8がDeflateであることを覚えておけばとりあえず良さそうです。zipは圧縮せずにアーカイバとして使うことも可能で、その場合は0になります。ファイルサイズが小さかったりで圧縮率が悪い場合も勝手に0になるようです。
また、CRC-32のフィールドや圧縮サイズ、非圧縮サイズなどもあります。そして汎用目的のビットフラグについてWikipediaの説明を引用しておきます。
汎用目的のビットフラグフィールドの3ビット目がセットされている場合、ヘッダの書き込み時にはCRC-32とファイルサイズが不明である。ローカルヘッダのCRC-32とファイルサイズのフィールドにはゼロが書き込まれ、CRC-32とファイルサイズは圧縮データの後ろに12バイトのデータとして追加される。(オプションの4バイトのシグネチャが前に付く場合もある。)
つまりCRC-32はファイル本体のあとにも置くことが出来るということです。これはdata descriptorと呼ばれる領域ですが、自分はこのヘッダの存在を知らず、これを知ってから色々腑に落ちた感じがあります。
Data descriptor
この領域は上で説明したようにオプショナルですが、存在する場合はCRC-32とサイズが入っています。
crc-32 4 bytes compressed size 4 bytes uncompressed size 4 bytes
なので実際には
- Local file header
- File data
- Data descriptor
の3つで1セットです。
セントラルディレクトリエントリ
以下のようになっています。ローカルファイルヘッダとかなり似た感じです。何で同じ値を複数持ってるのか疑問ですが、冗長性の確保のためとWikiには書いていました。ただ仕様の方ではそういった記述が見つけられなかったので未だに疑問です。
central file header signature 4 bytes (0x02014b50) version made by 2 bytes version needed to extract 2 bytes general purpose bit flag 2 bytes compression method 2 bytes last mod file time 2 bytes last mod file date 2 bytes crc-32 4 bytes compressed size 4 bytes uncompressed size 4 bytes file name length 2 bytes extra field length 2 bytes file comment length 2 bytes disk number start 2 bytes internal file attributes 2 bytes external file attributes 4 bytes relative offset of local header 4 bytes file name (variable size) extra field (variable size) file comment (variable size)
ここで重要なのはローカルファイルヘッダの相対オフセットです。これが上述したローカルファイルヘッダへの参照となります。つまりセントラルディレクトリエントリを見つければ実際のファイルにも飛べるということになります。
セントラルディレクトリの終端レコード
全てのセントラルディレクトリエントリの後に、ZIPファイルの終わりを表すセントラルディレクトリの終端レコードが続きます。
end of central dir signature 4 bytes (0x06054b50) number of this disk 2 bytes number of the disk with the start of the central directory 2 bytes total number of entries in the central directory on this disk 2 bytes total number of entries in the central directory 2 bytes size of the central directory 4 bytes offset of start of central directory with respect to the starting disk number 4 bytes .ZIP file comment length 2 bytes .ZIP file comment (variable size)
セントラルディレクトリへのオフセットが保存されています。展開時は、まず初めにセントラルディレクトリの終端レコードのシグネチャを探し、次に各セントラルレコードを探索し、ローカルファイルヘッダを探索するという処理の流れになります。
gzipからzipへの変換
ここまでgzipとzipのヘッダを見てきましたが、共通点が多くあったことがわかると思います。特に、どちらも圧縮メソッドとしてDeflateが利用可能な点、CRC-32を含む点は重要です。gzipはシンプルで、ヘッダ内で重要なのはファイル名と最終更新時刻ぐらいな気がします(暴論)。そしてtrailerにCRC-32とサイズが含まれています。これらの情報を流用すれば再計算なしにzipのローカルヘッダやセントラルヘッダが作れそうです。拡張ヘッダなどの諸々は一旦無視して、とりあえずzipファイルとして正しいフォーマットのものを作ることを目指します。
gzipをストリームに処理していきたいので、
の3つに分けて説明していきます。
gzipヘッダの処理
まずヘッダからファイル名と最終更新時刻を取り出します。次にzipのローカルファイルヘッダを作ります。compression methodにはDeflateを指定し、最終更新時刻もgzipから取り出したものを入れます。しかし、この時点ではCRC-32や非圧縮サイズは持っていません。そこで、上述したように汎用目的のビットフラグフィールドの3ビット目をセットし、CRC-32やcompressed/uncompressed sizeなどは全て0を埋めておきます。実際の値はdata descriptorに入れます。
あとはファイル名やファイル名の長さを入れればローカルファイルヘッダは完成です。後々セントラルディレクトリエントリでも同じ情報が必要になるのでこれらの情報は取っておきます。
ちなみにCRC-32はgzip trailerを読めば取得可能なので、一旦フッタを読んでseekして先頭に戻せば一応この時点でもCRC-32のフィールドを埋めることが出来ます。ただファイル自体が大きい場合はseekすら惜しいということでストリーム処理したかったのではないかと推測しています。そういった場合にはやはりdata descriptorを使うのが有用そうです。
簡略したイメージ図は以下です。この時作ったローカルファイルヘッダのオフセットがセントラルディレクトリの終端レコード作成時に必要なのでそれも取っておきます。

gzipファイル本体の処理
ここは同じDeflateで圧縮されているのでそのままでOKです。実際適当にzipとgzipを作って比べると本体部分が共通しています。
$ echo fooooooooooo > hello.txt $ zip hello hello.txt adding: hello.txt (deflated 54%) $ od -Ax -tx1z hello.zip 000000 50 4b 03 04 14 00 00 00 08 00 88 09 6a 54 38 e5 >PK..........jT8< 000010 35 2f 06 00 00 00 0d 00 00 00 09 00 1c 00 68 65 >5/............he< 000020 6c 6c 6f 2e 74 78 74 55 54 09 00 03 50 34 29 62 >llo.txtUT...P4)b< 000030 51 34 29 62 75 78 0b 00 01 04 f5 01 00 00 04 14 >Q4)bux.........< 000040 00 00 00 4b cb 47 00 2e 00 50 4b 01 02 1e 03 14 >...KG...PK.....< 000050 00 00 00 08 00 88 09 6a 54 38 e5 35 2f 06 00 00 >.......jT85/...< 000060 00 0d 00 00 00 09 00 18 00 00 00 00 00 01 00 00 >................< 000070 00 a4 81 00 00 00 00 68 65 6c 6c 6f 2e 74 78 74 >......hello.txt< 000080 55 54 05 00 03 50 34 29 62 75 78 0b 00 01 04 f5 >UT...P4)bux....< 000090 01 00 00 04 14 00 00 00 50 4b 05 06 00 00 00 00 >........PK......< 0000a0 01 00 01 00 4f 00 00 00 49 00 00 00 00 00 >....O...I.....< 0000ae $ gzip hello.txt $ od -Ax -tx1z hello.txt.gz 000000 1f 8b 08 08 50 34 29 62 00 03 68 65 6c 6c 6f 2e >....P4)b..hello.< 000010 74 78 74 00 4b cb 47 00 2e 00 38 e5 35 2f 0d 00 >txt.KG...85/..< 000020 00 00 >..< 000022
gzipはファイル名のあとに本体が来ているので 4b cb 47 から始まるところが本体ですが、上のzipでも共通していることが分かります。compression methodも共に8(Deflate)になっています。
ということで単にgzipファイルの本体部分をそのままzipに転用すればOKなので以下のようになります。spliceを使う場合は先頭のヘッダサイズをオフセットに指定してスキップし、最後trailerの8バイトを残してzipに流し込めば良いです。つまりこのファイルの内容をユーザ空間のメモリに載せる必要なしに処理可能です。

この時、spliceの戻り値から圧縮サイズが分かります。
gzip trailerの処理
gzip trailerからCRC-32と非圧縮サイズを取り出します。そしてそれらをdata descriptorに入れます。

ここまででファイルの1セットが完成です。あとはヘッダ処理時に取っておいたファイル名や最終変更時間、そして今取得したCRC-32やサイズを使ってセントラルディレクトリエントリを作ります。

セントラルディレクトリエントリが完成したら、計算しておいたオフセットを使ってセントラルディレクトリの終端レコードを作れば完成です。
複数gzipファイルの連結
gzipファイルが複数あっても同じです。gzipファイルをストリームに処理してローカルファイルヘッダ、ファイル本体、data descriptorの1セットを作ります。セントラルディレクトリエントリはファイルごとに作ったものをメモリ上で連結して保存しておいて、最後にzipファイルの末尾に置くだけです。
PoC
机上の空論なのではないかと不安だったので作ってみました。
内部でspliceを使っているのでパイプを使う必要があります。
$ go run main.go hello.txt.gz | cat - > hello.zip
これで作ったzipはきちんとunzipコマンドで正しく解凍できました。とりあえず確かめたかっただけなので拡張ヘッダはスキップしてますし(何なら最終更新時刻もサボった)ソースコードもゴリ押しですが、理解は深まったので良しとします。
報告者にソースコードを送りつけてこういうことだよね?と確認したので、細かい違いはあると思いますが大筋は間違ってないと思います。Linuxカーネルに特別詳しいわけでもないので、実はこの実装だと省メモリになってないよ、とかあったら教えて下さい。ただ報告者がやっていたのは少なくともこういうことで正しいはずです。
ちなみにDirty Pipeの脆弱性においてはspliceで最後8バイトは(trailerなので)パイプに送っていないというのがとても重要です。
まとめ
複数のgzipファイルをspliceを使いつつストリームに処理して高速かつ省メモリでzipファイルが作れることを確かめました。どっちのフォーマットも割と共通しているところが多いのでこういった事が可能なんだなと感心しました。元のブログではgzipファイルをそのまま連結しているという書き方でしたが、実際にはDeflate圧縮された部分を取り出して連結している、が正しい表現かな気がします。本筋から外れるので説明を簡略したのかなと思います。
しかしDirty Pipeの解説を書くはずが自分は一体何を...