次から次へと発表するなと思っていたのですが、これらは実はProject AmeriaというプロジェクトでForescout Research LabsとJSOF Research Labsが共同で研究した成果だったようです。何というか楽しそうですね。まだプロジェクトは終わっていないようなので、今後もAmeriaから新たに脆弱性が出るかもしれません。今後の動向に注目する必要があります。
ここで DNS_Unpack_Domain_Name() の実装に話を戻すと、whileループはNULLが来るまで終わらないようになっています。そして各ラベルは23行目で63バイトに制限されていますが( size & 0x3f)、実際に name にコピーされるトータルのサイズについてはチェックがありません。つまり攻撃者が意図的に大きい値を入れてしまえば全て name ( DNS_Unpack_Domain_Name() では dst )にコピーされます。しかし name は255バイトしか確保されていないため、領域外に対して書き込まれてしまいます。結果としてヒープを破壊し、RCEに繋がる可能性があります。これは典型的なヒープオーバーフローであり実際のペイロードの組み立て方に関する詳細はAMNESIA:33のホワイトペーパーで説明されています。
name のヒープオーバーフローを起こさせる簡単な方法は、各ラベルを63バイトにしてトータルのサイズが255バイトを超えるようにして name に書き込ませる方法です。自分としてはこの脆弱性だけで十分悪用できるのに何で前述のCVE-2020-27009と組み合わせる必要があるのかと疑問だったのですが、それについても説明されていました。まず各ラベルが63バイトで255バイトを超えるようなバイト列はDNSパケットにとっては大きすぎます。さらにIDS等に検知される可能性があります。そこで、小さいペイロードでオーバーフローをこすためにCVE-2020-27009が利用できます。
The vulnerability exists due to a boundary error when parsing option 119 data in DHCP packets in dhclient(8). A remote attacker on the local network can send specially crafted data to the DHCP client, trigger heap-based buffer overflow and execute arbitrary code on the target system.
int
find_search_domain_name_len(struct option_data *option, size_t *offset)
{
int domain_name_len, label_len, pointed_len;
size_t i, pointer;
domain_name_len = 0;
i = *offset;
while (i < option->len) {
label_len = option->data[i];
if (label_len == 0) {
/* * A zero-length label marks the end of this * domain name. */
*offset = i + 1;
return (domain_name_len);
} elseif (label_len & 0xC0) {
/* This is a pointer to another list of labels. */if (i + 1 >= option->len) {
/* The pointer is truncated. */
warning("Truncated pointer in DHCP Domain ""Search option.");
return (-1);
}
pointer = ((label_len & ~(0xC0)) << 8) +
option->data[i + 1];
if (pointer >= *offset) {
/* * The pointer must indicate a prior * occurrence. */
warning("Invalid forward pointer in DHCP ""Domain Search option compression.");
return (-1);
}
pointed_len = find_search_domain_name_len(option,
&pointer);
if (pointed_len < 0)
return (-1);
domain_name_len += pointed_len;
*offset = i + 2;
return (domain_name_len);
}
if (i + label_len >= option->len) {
warning("Truncated label in DHCP Domain Search ""option.");
return (-1);
}
/* * Update the domain name length with the length of the * current label, plus a trailing dot ('.'). */
domain_name_len += label_len + 1;
/* Move cursor. */
i += label_len + 1;
}
warning("Truncated DHCP Domain Search option.");
return (-1);
}
void
expand_search_domain_name(struct option_data *option, size_t *offset,
unsignedchar **domain_search)
{
int label_len;
size_t i, pointer;
unsignedchar *cursor;
/* * This is the same loop than the function above * (find_search_domain_name_len). Therefore, we remove checks, * they're already done. Here, we just make the copy. */
i = *offset;
cursor = *domain_search;
while (i < option->len) {
label_len = option->data[i];
if (label_len == 0) {
/* * A zero-length label marks the end of this * domain name. */
*offset = i + 1;
*domain_search = cursor;
return;
} elseif (label_len & 0xC0) {
/* This is a pointer to another list of labels. */
pointer = ((label_len & ~(0xC0)) << 8) +
option->data[i + 1];
expand_search_domain_name(option, &pointer, &cursor);
*offset = i + 2;
*domain_search = cursor;
return;
}
/* Copy the label found. */
memcpy(cursor, option->data + i + 1, label_len);
cursor[label_len] = '.';
/* Move cursor. */
i += label_len + 1;
cursor += label_len + 1;
}
}
This is the same loop than the function above (find_search_domain_name_len). Therefore, we remove checks, they're already done. Here, we just make the copy.
これは正しく動きます。まず長さ1の A というラベルが取り出されます。そしてその次がNULLになっているので終端し、 A. というドメイン名になります。そして次のドメイン名取り出しのループになり、 0xc0 が参照されます。そしてオフセットが計算され、0であるため先頭を参照します。つまり A. というドメイン名とそれを参照して得られた A. というドメイン名の2つが含まれることになります。
Aqua Securityの提供する1スキャナーが認定を受けたので嘘ではないのですが、誤解を招きそうだなということでここは正直に書いておきます。というか今回の認定プログラムの実装にAquaで関わったのは自分だけです。それでいて次々と問題が見つかってRed Hatへの説明を一人で頑張る日々を過ごしていて辛かったのですが、 @masahiro331 が自分の実装の検証を手伝ってくれたり一部実装してくれたりとAqua社員でないにも関わらず副業として色々と手伝ってくれました。最初の方はずっと一人でやっていて上の理由でメンタルをやられつつあったので、手伝ってもらって本当に助かりました。
この例ではsambaというパッケージがRed Hat Enterprise LinuxとRed Hat Storage 3で提供されています。Red Hat Storage 3をスキャンしている場合にRed Hat Enterprise Linuxのセキュリティアドバイザリを使ってしまうと誤検知になるわけですが、そこの判定が現在のRed Hatのスキャン仕様では出来ません。両方のプラットフォームでRHSAが提供されていて、かつバージョニングが異なる場合にのみ起こるので頻繁に起こるようなものではありません。大量にスキャンした中で数件しか見つかりませんでした。とはいえ0ではないので少し頭に入れておくとおかしな結果が出たときに疑えるかもしれません。
Red Hatの実際に開発している人たちに確認しましたが、仕様的な問題で現時点では直しようがないそうです。つまり全てのスキャナーで同じことが起きます。今回の認定用に新たに作った仕様なので今から直せば何とかならないのかなと思いましたが、既に多くの会社を巻き込んでしまっていたので修正は難しかったようです。
$ go version -m /usr/local/bin/terraform
/usr/local/bin/terraform: go1.14.9
path github.com/hashicorp/terraform
mod github.com/hashicorp/terraform (devel)
dep cloud.google.com/go v0.45.1
dep github.com/Azure/azure-sdk-for-go v45.0.0+incompatible
dep github.com/Azure/go-autorest/autorest v0.11.3
dep github.com/Azure/go-autorest/autorest/adal v0.9.0
dep github.com/Azure/go-autorest/autorest/azure/cli v0.4.0
dep github.com/Azure/go-autorest/autorest/date v0.3.0
dep github.com/Azure/go-autorest/autorest/to v0.4.0
dep github.com/Azure/go-autorest/autorest/validation v0.3.0
知らなかったといいつつバイナリにmoduleの情報が含まれていることは以前から知っていて、どうやって取り出すのかなとずっと頭の片隅にはあったのですが、 go version で取り出せるということを今更ながら知りました。自分の開発しているOSSにとってこれは非常にありがたい情報で、面白い機能が実装できるようになります。これは後の余談で話します。
確かにmodule情報が含まれていることが分かります。念の為 go version -m を見てみます。
$ go version -m ./utern
./utern: go1.15.2
path github.com/knqyf263/utern
mod github.com/knqyf263/utern (devel)
dep github.com/aws/aws-sdk-go v1.25.36 h1:4+TL/Y2G5hsR1zdfHmjNG1ou1WEqsSWk8v7m1GaDKyo=
dep github.com/briandowns/spinner v1.7.0 h1:aan1hBBOoscry2TXAkgtxkJiq7Se0+9pt+TUWaPrB4g=
dep github.com/cpuguy83/go-md2man/v2 v2.0.0 h1:EoUDS0afbrsXAZ9YQ9jdu/mZ2sXgT1/2yyNng4PGlyM=
dep github.com/fatih/color v1.7.0 h1:DkWD4oS2D8LGGgTQ6IvwJJXSL5Vp2ffcQg58nFV38Ys=
dep github.com/jmespath/go-jmespath v0.0.0-20180206201540-c2b33e8439af h1:pmfjZENx5imkbgOkpRUYLnmbU7UEFbjtDA2hxJ1ichM=
dep github.com/mattn/go-colorable v0.1.4 h1:snbPLB8fVfU9iwbbo30TPtbLRzwWu6aJS6Xh4eaaviA=
dep github.com/mattn/go-isatty v0.0.10 h1:qxFzApOv4WsAL965uUPIsXzAKCZxN2p9UqdhFS4ZW10=
dep github.com/pkg/errors v0.8.1 h1:iURUrRGxPUNPdy5/HRSm+Yj6okJ6UtLINN0Q9M4+h3I=
dep github.com/russross/blackfriday/v2 v2.0.1 h1:lPqVAte+HuHNfhJ/0LC98ESWRz8afy9tM/0RK8m9o+Q=
dep github.com/shurcooL/sanitized_anchor_name v1.0.0 h1:PdmoCO6wvbs+7yrJyMORt4/BmY5IYyJwS/kOiWx8mHo=
dep github.com/urfave/cli v1.22.1 h1:+mkCCcOFKPnCmVYVcURKps1Xe+3zP90gSYGNfRkjoIY=
dep golang.org/x/sys v0.0.0-20191115151921-52ab43148777 h1:wejkGHRTr38uaKRqECZlsCsJ1/TGxIyFbH32x5zUdu4=
上に含まれているデータと同じになっているようです。何かシリアライズされていて入っていて、 go version が整形して出しているのかと思いきや普通に上の表示のまま入っています。つまり改行やタブなどがそのままです。プログラムで使いたい場合は逆に整形する必要があります。
ちなみにgo.modの中でreplaceを使っている場合などは dep のところが => になったりします。
ということで簡単にGoバージョンとmodule情報を取得することが出来ました。 go version はELFだけでなくPEやMach-Oにも対応しています。
$ GOOS=linux GOARCH=amd64 go build -ldflags'-w -s' .
$ go version -m ./utern
./utern: go1.15.2
path github.com/knqyf263/utern
mod github.com/knqyf263/utern (devel)
dep github.com/aws/aws-sdk-go v1.25.36 h1:4+TL/Y2G5hsR1zdfHmjNG1ou1WEqsSWk8v7m1GaDKyo=
dep github.com/briandowns/spinner v1.7.0 h1:aan1hBBOoscry2TXAkgtxkJiq7Se0+9pt+TUWaPrB4g=
...
それで色々調べた結果、 go version が既に対応していることを知り、自分でも実装することが出来ました。以前ブログにも書いたのですが、Issueでユーザの方から教えてもらうことがとても多くていつも助かっています。情報の価値が高い現代において欲しい情報が勝手に集まってくるOSSは良いものだなと思います。
dnsmasqのフォワーダはDNSクエリを上流のキャッシュサーバに転送するわけですが、その時に利用されるソケットの最大数は64となっています。各ソケットはランダムなソースポート番号が使われるため、dnsmasqはソースポート番号のランダム化(Source Port Randimization, SPR)が有効になっていると言えます。TXIDと合わせると32bitのエントロピーとなるわけですが、実装の問題によりそうはなっていなかったというのがこの脆弱性です。
繰り返し述べているようにレスポンスに含まれるTXIDはリクエスト時のTXIDと等しい必要があります。もちろん単にTXIDが等しければよいというわけではなくてQuestionセクションも等しい必要があります。このQuestionセクションはどのようなドメイン名のどのようなレコードタイプ・クラスを問い合わせていたか、というものが含まれています。例を上げると www.example.com A IN のようなものです。dnsmasqではQuestionセクションの検証のためにこれらの値をそのまま用いるのではなくハッシュを用います。
#!/usr/bin/pythonfrom scapy.all import *
defpacket_handler(pkt):
if pkt.haslayer(DNSQR) and pkt.haslayer(UDP):
print(f"Source port: {pkt[UDP].sport}, TXID: {pkt[DNS].id}, Query: {pkt[DNSQR].qname}")
print("Sniffing...")
sniff(filter="udp port 53 and ip src 10.10.0.2", prn=packet_handler)
s = conf.L2socket(iface="eth0")
for txid, sport in candidates:
# update TXID and UDP dst port
patch(dns_frame, pseudo_hdr, txid, sport)
s.send(dns_frame)
今回の脆弱性はServiceのtype: LoadBalancer/ClusterIPを悪用して行う中間者攻撃(MITM)なのですが、ブログの中でMITM as a Serviceと評していたのが面白かったです。KubernetesがMITMを簡単に代行してくれるという意味でas a Service感強いですし、今回悪用するリソースタイプもServiceなので二重にかかっていて好きです。
このようにDNSというのはいくつかのレイヤーがありますが、このうちAuthoritative name servers(以下、権威サーバ)以外に対して有効な手法です。論文中では主に影響の大きさからForwarderとRecursive Resolverについて解説しています。このブログでは簡単のためRecursive Resolver(以下、リゾルバ)に絞って説明します。
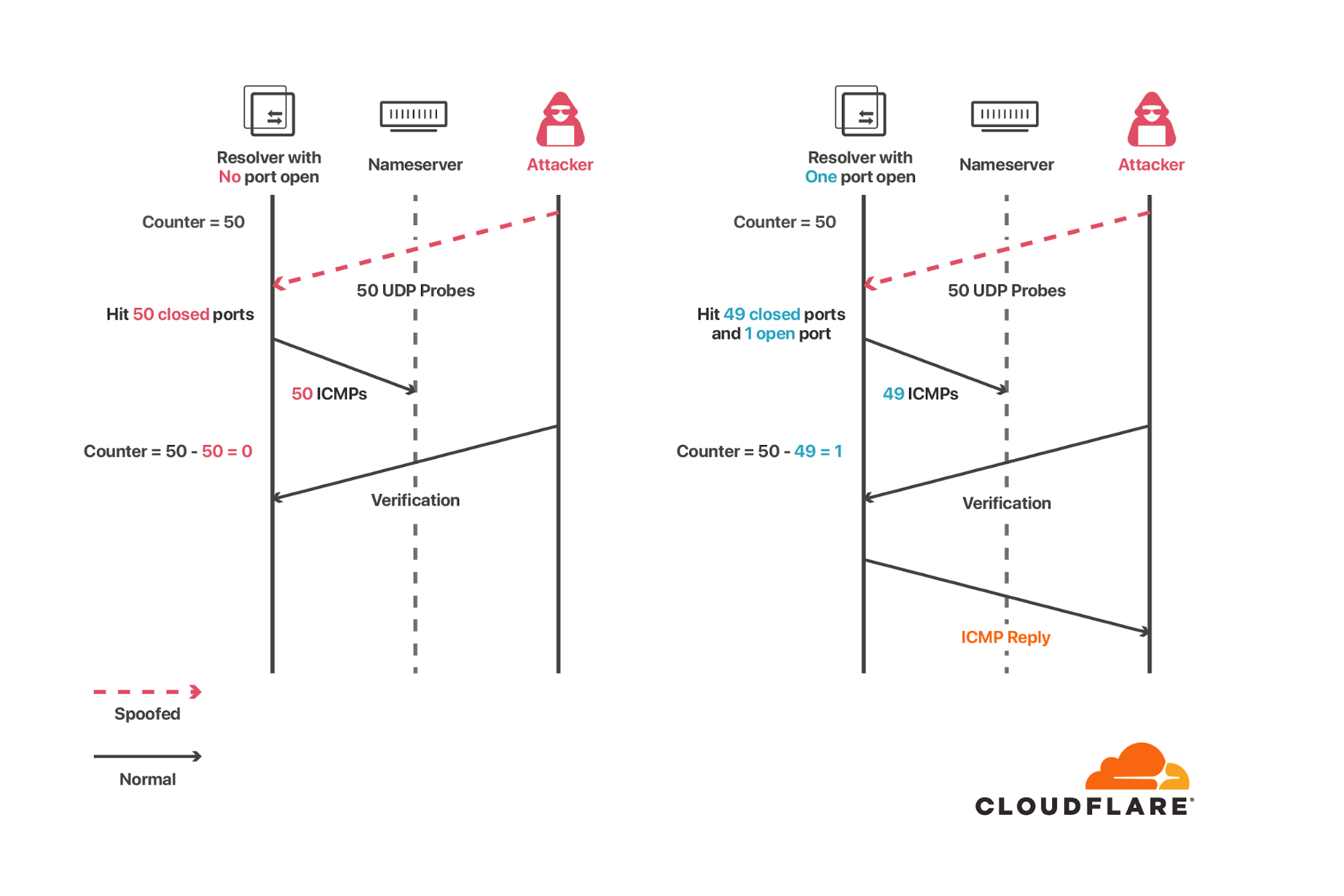
話を戻すと、1の実装の場合はDNSリゾルバがクエリを投げる時、そのソースポートはオープン状態になります。つまり攻撃者が任意のIPアドレスからポートスキャンをすると、クローズな場合はICMP port unreachableが返ってきますがオープンな時はICMPが返ってきません。この挙動を観察することで攻撃者は容易にソースポートを推測することが出来ます。ソースポートさえ分かってしまえば、あとは16bitのQuery IDを推測するだけなので攻撃実現性はかなり高まります。
ICMP rate limit
容易に推測可能と言いましたが、実際には対策が入っておりそこまで簡単ではありません。なぜかと言うとLinuxなどの主要OSにはICMPエラーを返す際のrate limitが設定されているためです。先程のICMP port unreachableは1秒あたりに返せる量の上限があるため、高速にスキャンすることが出来ません。
上記はすべて20ms以内に行う必要があります。20msを超えるとトークンが回復してしまうためです。先ほど説明したように20ms以内に送れるICMPエラーメッセージの数はicmp_msgs_burstによって制御されています。つまり全てのポートがcloseな場合、既に50個のICMP port unreachableが返されてrate limitの上限に達しています。その状態で検証用UDPパケットを送ってもrate limitのためにICMPエラーは返ってきません。
ということでポートが開いている場合と開いていない場合で、最後の検証用UDPパケットに対する挙動が異なります。1つでもポートが開いていればICMP port unreachableが返ってくるし、全て閉じていれば返ってきません。これで指定した50ポートの中にオープンなものがあることが分かるため、あとは二分探索などを適当にすればオープンポートを突き止められます。

















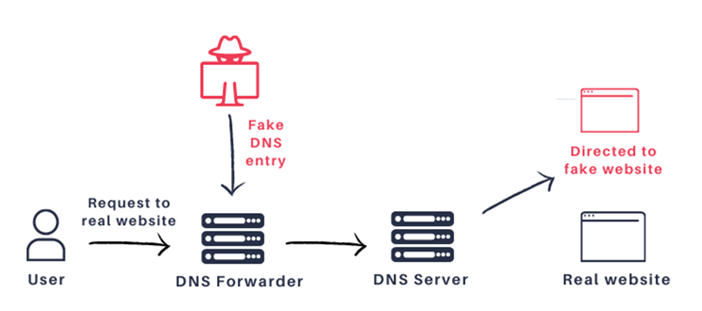



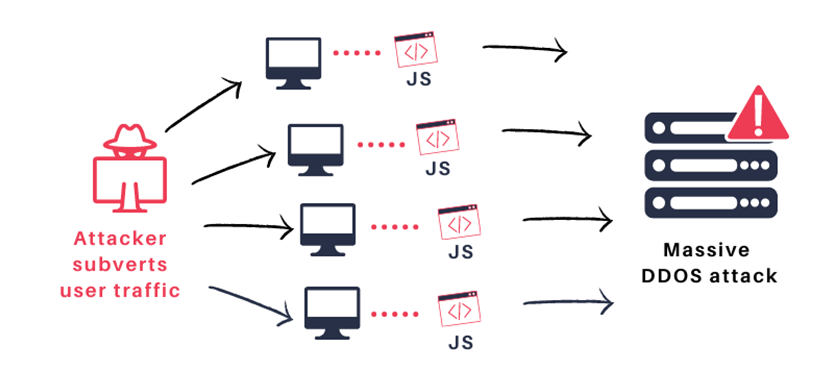 *JSOFの
*JSOFの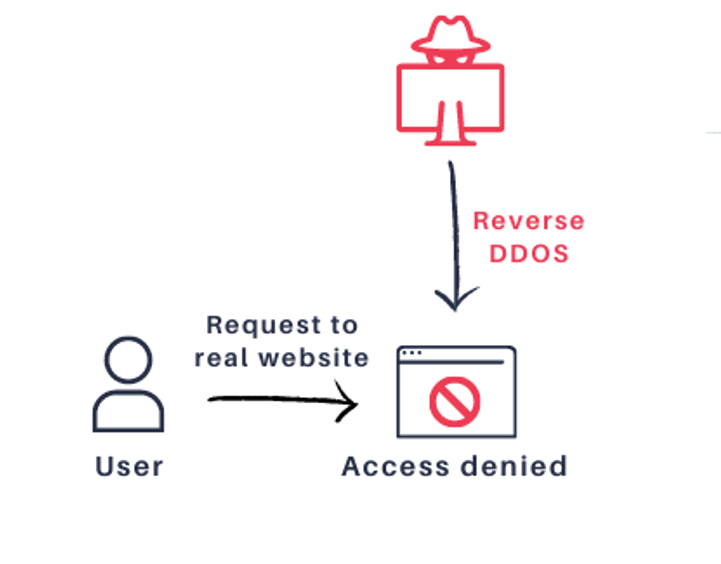 *JSOFの
*JSOFの